pak::pak("guilhermegarcia/fonology")
# Alternative :
remotes::install_github("guilhermegarcia/fonology")La bibliothèque Fonology
Analyse phonologique avec R
 Le package
Le package Fonology (Garcia, 2026) propose différentes fonctions utiles pour la recherche en phonologie et pour son enseignement. Si vous avez des suggestions ou des commentaires, consultez la page GitHub du projet. Vous y trouverez aussi une page de discussions pour les questions générales. N’hésitez pas à ouvrir un issue pour aider à améliorer le package. Pour l’installer, utilisez l’une des commandes ci-dessous.
![]()
![]()


AstuceLa version 1.2.0 est arrivée
Les cinq langues utilisent maintenant une consultation lexicale avant de revenir aux règles par expressions régulières : de nouveaux lexiques dérivés du Wiktionnaire ont été ajoutés pour l’italien (~82 k mots) et l’espagnol (~130 k mots), rejoignant les lexiques existants pour l’anglais (CMU), le français (Lexique 4) et le portugais (PSL). Les mots absents du lexique sont transcrits par règles et signalés par un * final, et les transcriptions par règles ont été considérablement améliorées pour toutes les langues (voir le tableau de précision ci-dessous). Les entrées définies avec add_lex_pt() et ses équivalents ont toujours la priorité.
Installation
Fonctions principales et données
ipa()transcrit phonémiquement des mots (réels ou non) en anglais, en français, en italien, en portugais et en espagnolgetFeat()etgetPhon()pour travailler avec les traits distinctifssyllable()extrait les constituants syllabiquesmaxent()construit une grammaire MaxEnt (voir aussinhg())sonDisp()calcule la dispersion de sonorité d’une demi-syllabe donnée ou la dispersion moyenne d’un ensemble de mots; voir aussimeanSonDisp()pour la moyenne d’un motplotSon()trace le profil de sonorité d’un mot donnébiGram_pt()calcule les probabilités de bigrammes d’un mot donnéwug_pt()génère des mots hypothétiques en portugaisplotVowels()génère des trapèzes vocaliquesipa2tipa()convertit des séquences API en séquencestipa(voir aussiipa2typst())monthsAge()etmeanAge()add_lex_pt()et ses équivalents (_en,_fr,_it,_sp) permettent d’ajouter vos propres entrées aux lexiques utilisés paripa(); voir aussiremove_lex_pt()(et équivalents) etexport_lex()pslcontient le Portuguese Stress Lexiconpt_lexcontient une version simplifiée depslen_lex,fr_lex,it_lexetsp_lexcontiennent les lexiques de consultation utilisés paripa(): dérivés de CMU pour l’anglais, de Lexique 4 pour le français et du Wiktionnaire (via Wiktextract/kaikki.org) pour l’italien et l’espagnolstopwords_pt,stopwords_en,stopwords_fr,stopwords_itetstopwords_spcontiennent des mots-outils en portugais, en anglais, en français, en italien et en espagnol
Transcription API
La fonction ipa() prend un word (ou un vecteur contenant plusieurs mots, réels ou non) dans sa forme orthographique et renvoie sa transcription phonémique (c.-à-d. large), avec la syllabation et l’accent. Cinq langues sont actuellement prises en charge : l’anglais, le français, l’italien, le portugais et l’espagnol. Les cinq langues utilisent d’abord une consultation lexicale : les mots trouvés dans le lexique de la langue reçoivent leur transcription de dictionnaire, et seuls les mots hors vocabulaire (mots fictifs, formes rares, noms propres) sont transcrits par des règles à base d’expressions régulières. Les transcriptions dérivées des règles sont signalées par un * final; les fonctions auxiliaires ignorent ce marqueur, donc les formes ainsi signalées peuvent circuler sans problème dans le reste du package. Une transcription étroite est disponible pour le portugais (sur la base du portugais brésilien), y compris l’accent secondaire; pour l’obtenir, ajoutez narrow = T à la fonction. Exécutez ipa_pt_test(), ipa_en_test(), ipa_fr_test(), ipa_it_test() et ipa_sp_test() pour voir des exemples. Par défaut, ipa() suppose que lg = "Portuguese" (ou lg = "pt") et narrow = F.
library(Fonology)
ipa("comfortably", lg = "en")
#> [1] "ˈkʌm.fɚ.tə.bli"
ipa("atlético")
#> [1] "a.ˈtlɛ.ti.ko"
ipa("antidepressivo", narrow = T)
#> [1] "ˌãn.t͡ʃi.ˌde.pɾe.ˈsi.vʊ"
ipa("nuevos", lg = "sp")
#> [1] "ˈnwe.bos"
ipa("informatique", lg = "fr")
#> [1] "ɛ̃.fɔʁ.ma.tik"
ipa("stazione", lg = "it")
#> [1] "stat.ˈtsjo.ne"
ipa("blimpo") # mot fictif : transcription par règles, signalée par *
#> [1] "ˈblim.po*"Quelle confiance accorder à chaque voie? Les transcriptions issues de la consultation sont, par construction, de qualité dictionnairique. Les règles de repli sont évaluées sur 4 000 mots réservés de chaque lexique (correspondance exacte, y compris l’accent et la syllabation); la couverture en tokens est mesurée sur des échantillons de texte courant. Notez le compromis : les langues à orthographe transparente (l’espagnol, le portugais) dépendent à peine de leur lexique, tandis que l’anglais repose presque entièrement sur la consultation.
| Langue | Source de consultation | Entrées | Couverture (tokens) | Règles (exact) | Global |
|---|---|---|---|---|---|
| anglais | CMU Pronouncing Dictionary | ~133 k | ~99,9 % | 27 % | ~99,9 % |
| français | Lexique 4 | ~171 k | ~99 % | 71 % | ~99 % |
| espagnol | Wiktionnaire (kaikki.org) | ~130 k | ~83 % | 95 % | ~98 % |
| italien | Wiktionnaire (kaikki.org) | ~82 k | ~92 % | 70 % | ~97 % |
| portugais | Portuguese Stress Lexicon | ~129 k | ~25 % | 95 % | ~94 % |
| Couverture de l'espagnol mesurée sur un texte classique; elle est plus élevée sur des textes modernes. Le PSL ne contient que des non-verbes : les mots-outils et les verbes du portugais sont donc traités par les règles de repli (qui ont une précision quasi dictionnairique). | |||||
Personnaliser les transcriptions
Si une transcription est erronée—ou si un emprunt résiste aux règles—vous pouvez ajouter vos propres entrées, qui ont priorité à la fois sur le lexique et sur les règles. Les entrées persistent dans votre installation locale d’une session à l’autre.
# Portugais, espagnol, italien : les formes diacritées règlent
# l'accent et la qualité vocalique
add_lex_it("chièdere") # è marque l'accent + la voyelle mi-ouverte
# Ou stockez une transcription API exacte pour n'importe quelle langue :
add_lex_pt("shampoo", ipa = "ʃam.ˈpu")
add_lex_en("naive", ipa = "na.ˈiv")
ipa("shampoo") # renvoie ʃam.ˈpu tel quel
export_lex("pt", "mon_api.tsv", ipa = TRUE) # partager vos entrées API
AvertissementUne remarque sur la reproductibilité
Les entrées ajoutées avec add_lex_*() sont stockées sur votre machine (sous tools::R_user_dir()), et non dans votre script. Pour toute analyse destinée à être partagée ou publiée, déclarez vos entrées au début du script—les appels sont idempotents, donc réexécutables sans risque—ou distribuez-les avec export_lex(). Et si un mot courant est mal transcrit, ouvrez plutôt un issue : la correction profitera à tout le monde.
Fonctions auxiliaires
Si vous voulez tokeniser des textes et créer un tableau avec des colonnes distinctes pour l’accent et les syllabes, vous pouvez utiliser quelques fonctions auxiliaires simples. Par exemple, getWeight() prend un mot syllabé et renvoie son profil de poids (p. ex., getWeight("kon.to") renvoie HL). La fonction getStress() renvoie la position de l’accent dans un mot donné (jusqu’à l’antépénultième) ; le mot doit déjà être accentué, mais le symbole utilisé pour l’accent peut être spécifié avec l’argument stress. La fonction peut aussi extraire la syllabe accentuée avec l’argument syl = TRUE. Enfin, countSyl() renvoie le nombre de syllabes dans une chaîne, et getSyl() extrait une syllabe particulière d’une chaîne. Par exemple, getSyl(word = "kom-pu-ta-doɾ", pos = 3, syl = "-") extrait l’antépénultième syllabe de la chaîne en question (vous pouvez modifier la direction de l’analyse avec l’argument dir). Le symbole par défaut pour la syllabation est le point.
Voici un exemple simple montrant comment tokeniser un texte et créer un tableau avec des variables codées à l’aide des fonctions présentées jusqu’ici, sans passer par des packages comme tm ou tidytext; notez aussi l’utilisation de cleanText().
library(tidyverse)
text = "Por exemplo, em quase todas as variedades do português..."
d = tibble(word = text |>
cleanText())
d = d |>
mutate(IPA = ipa(word),
stress = getStress(IPA),
weight = getWeight(IPA),
syl3 = getSyl(IPA, 3),
syl2 = getSyl(IPA, 2),
syl1 = getSyl(IPA, 1),
syl_st = getStress(IPA, syl = TRUE)) |> # syllabe accentuée
filter(!word %in% stopwords_pt) # supprimer les mots-outils| word | IPA | stress | weight | syl3 | syl2 | syl1 | syl_st |
|---|---|---|---|---|---|---|---|
| quase | ˈkwa.ze* | penult | LL | NA | kwa | ze | kwa |
| variedades | va.ri.e.ˈda.des* | penult | LLH | e | da | des | da |
| português | por.tu.ˈges | final | HLH | por | tu | ges | ges |
Il est souvent utile d’extraire les attaques, noyaux, codas et rimes à partir des syllabes. C’est précisément ce que fait syllable() : à partir d’une syllabe (phonémiquement transcrite), la fonction renvoie le constituant qui vous intéresse. Ajoutons des colonnes à d pour extraire tous les constituants de la syllabe finale (colonne syl1).
d = d |>
select(-c(syl3, syl2, stress)) |>
mutate(on1 = syllable(syl = syl1, const = "onset"),
nu1 = syllable(syl = syl1, const = "nucleus"),
co1 = syllable(syl = syl1, const = "coda"),
rh1 = syllable(syl = syl1, const = "rhyme"))| word | IPA | weight | syl1 | syl_st | on1 | nu1 | co1 | rh1 |
|---|---|---|---|---|---|---|---|---|
| quase | ˈkwa.ze* | LL | ze | kwa | z | e | NA | e |
| variedades | va.ri.e.ˈda.des* | LLH | des | da | d | e | s | es |
| português | por.tu.ˈges | HLH | ges | ges | g | e | s | es |
Il faut décider si l’on souhaite traiter les glides comme faisant partie des attaques ou des codas, ou si l’on préfère les inclure uniquement dans les noyaux. Par défaut, syllable() suppose que tous les glides sont nucléaires. Vous pouvez modifier cela en utilisant glides_as_onsets = T et glides_as_codas = T (les deux arguments étant définis par défaut sur F).
AstuceVous avez beaucoup de données?
Si vous avez un très grand nombre de mots à analyser avec des fonctions comme ipa() ou syllable(), il est beaucoup plus rapide d’exécuter d’abord ces fonctions sur les types, puis d’étendre les variables créées à tous les tokens (par exemple, avec right_join() du package dplyr).
Transcription API des lemmes
Vous pouvez facilement combiner Fonology avec d’autres packages qui offrent des capacités d’étiquetage. Dans l’exemple ci-dessous, nous importons un court extrait de Os Lusíadas, nous l’annotons avec udpipe (Wijffels, 2023), puis nous transcrivons uniquement les noms du jeu de données.
library(udpipe)
udpipe_model_file = "portuguese-gsd-ud-2.5-191206.udpipe"
if (!file.exists(udpipe_model_file)) {
# Télécharger le modèle une seule fois, puis réutiliser le fichier local.
udpipe_download_model(language = "portuguese-gsd")
}
udmodel_pt = udpipe_load_model(file = udpipe_model_file)
lus_file = if (file.exists("data_files/lus.txt")) {
"data_files/lus.txt"
} else {
"../quarto_website/data_files/lus.txt"
}
txt_pt = read_lines(lus_file) |>
str_to_lower()
set.seed(1)
annotation_pt = udpipe_annotate(udmodel_pt, txt_pt) |>
as_tibble() |>
select(sentence, token, lemma, upos)
lusiadas = annotation_pt |>
select(lemma, upos) |>
filter(upos == "NOUN",
!is.na(lemma)) |>
mutate(ipa = ipa(lemma),
stress = getStress(ipa)) |>
select(-upos) |>
ungroup()| lemma | ipa | stress |
|---|---|---|
| arma | ˈar.ma | penult |
| barão | ba.ˈrãw̃ | final |
| praia | ˈpra.ja | penult |
| mar | ˈmar* | final |
| taprobana | ta.pro.ˈba.na* | penult |
Grammaires probabilistes
La fonction maxent() estime les poids dans une grammaire à entropie maximale (Goldwater & Johnson, 2003; Hayes & Wilson, 2008; Wilson, 2006) à partir d’un objet tableau contenant les inputs, outputs, contraintes, violations et observations (voir la documentation). La fonction renvoie une liste de différents objets, notamment les poids appris, la valeur du BIC et les probabilités prédites pour chaque output. Si vous souhaitez mener une analyse MaxEnt plus complète, je recommande vivement le package maxent.ot, qui est exclusivement consacré aux grammaires MaxEnt (Mayer et al., 2024). Voici un exemple d’utilisation de maxent().
maxent_data <- tibble::tibble(
input = rep(c("pad", "tab", "bid", "dog", "pok"), each = 2),
output = c("pad", "pat", "tab", "tap", "bid", "bit", "dog", "dok", "pog", "pok"),
ident_vce = c(0, 1, 0, 1, 0, 1, 0, 1, 1, 0),
no_vce_final = c(1, 0, 1, 0, 1, 0, 1, 0, 1, 0),
obs = c(5, 15, 10, 20, 12, 18, 12, 17, 4, 8)
)
maxent(tableau = maxent_data)
#> $predictions
#> # A tibble: 10 × 12
#> input output ident_vce no_vce_final obs harmony max_h exp_h Z obs_prob
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 pad pad 0 1 5 0.639 0.639 1 2.79 0.25
#> 2 pad pat 1 0 15 0.0541 0.639 1.79 2.79 0.75
#> 3 tab tab 0 1 10 0.639 0.639 1 2.79 0.333
#> 4 tab tap 1 0 20 0.0541 0.639 1.79 2.79 0.667
#> 5 bid bid 0 1 12 0.639 0.639 1 2.79 0.4
#> 6 bid bit 1 0 18 0.0541 0.639 1.79 2.79 0.6
#> 7 dog dog 0 1 12 0.639 0.639 1 2.79 0.414
#> 8 dog dok 1 0 17 0.0541 0.639 1.79 2.79 0.586
#> 9 pok pog 1 1 4 0.693 0.693 1 3.00 0.333
#> 10 pok pok 0 0 8 0 0.693 2.00 3.00 0.667
#> # ℹ 2 more variables: pred_prob <dbl>, error <dbl>
#>
#> $weights
#> ident_vce no_vce_final
#> 0.05410682 0.63904035
#>
#> $log_likelihood
#> [1] -78.72152
#>
#> $log_likelihood_norm
#> [1] -7.872152
#>
#> $bic
#> [1] -152.8379Enfin, quelques fonctions sont consacrées aux grammaires harmoniques bruitées. Il s’agit d’outils pédagogiques qui permettent de montrer comment les probabilités sont générées à partir des poids de contraintes et des profils de violations de différents candidats. La fonction nhg() prend un objet tableau et renvoie les probabilités prédites à partir de n simulations. L’utilisateur peut aussi définir l’écart type du bruit utilisé. La fonction plotNhg() permet de visualiser comment différents écarts types influencent les probabilités des candidats après 100 simulations.
Traits distinctifs
La fonction getFeat() prend un ensemble de phonèmes ph et une langue lg. Elle renvoie la matrice minimale des traits distinctifs pour ph, compte tenu de l’inventaire phonémique de lg. Cinq langues sont prises en charge : l’anglais, le français, l’italien, le portugais et l’espagnol. Vous pouvez aussi utiliser un inventaire phonémique personnalisé. Voir les exemples ci-dessous.
La fonction getPhon() prend une matrice de traits ft (un simple vecteur en R) et une langue lg. Elle renvoie l’ensemble des phonèmes représentés par ft compte tenu de l’inventaire phonémique de lg. Les langues prises en charge sont les mêmes que pour getFeat(), et vous pouvez à nouveau fournir votre propre inventaire phonémique.
library(Fonology)
getFeat(ph = c("i", "u"), lg = "English")
#> [1] "+hi" "+tense"
getFeat(ph = c("i", "u"), lg = "French")
#> [1] "Not a natural class in this language."
getFeat(ph = c("i", "y", "u"), lg = "French")
#> [1] "+syl" "+hi"
getFeat(ph = c("p", "b"), lg = "Portuguese")
#> [1] "-son" "-cont" "+lab"
getFeat(ph = c("k", "g"), lg = "Italian")
#> [1] "+cons" "+back"library(Fonology)
getPhon(ft = c("+syl", "+hi"), lg = "French")
#> [1] "u" "i" "y"
getPhon(ft = c("-DR", "-cont", "-son"), lg = "English")
#> [1] "t" "d" "b" "k" "g" "p"
getPhon(ft = c("-son", "+vce"), lg = "Spanish")
#> [1] "z" "d" "b" "ʝ" "g" "v"library(Fonology)
getFeat(ph = c("p", "f", "w"),
lg = c("a", "i", "u", "y", "p",
"t", "k", "s", "w", "f"))
#> [1] "-syl" "+lab"
getPhon(ft = c("-son", "+cont"),
lg = c("a", "i", "u", "s", "z",
"f", "v", "p", "t", "m"))
#> [1] "s" "z" "f" "v"Sonorité
Trois fonctions du package servent à analyser la sonorité. D’abord, demi(word = ..., d = ...) extrait soit la première (d = 1, la valeur par défaut), soit la seconde (d = 2) demi-syllabe d’un mot donné (syllabé) ou d’un vecteur de mots. Ensuite, sonDisp(demi = ...) calcule le score de dispersion de sonorité d’une demi-syllabe, d’après Clements (1990) (voir aussi Parker (2011)). Cette métrique ne différencie pas les séquences qui respectent le principe de séquencement de la sonorité (SSP) de celles qui ne le respectent pas; autrement dit, pla et lpa auront le même score. Pour cette raison, une troisième fonction existe, ssp(demi = ..., d = ...), qui évalue si une demi-syllabe respecte (1) ou non (0) le SSP. Dans l’exemple ci-dessous, le score de dispersion est calculé pour la première demi-syllabe de la pénultième syllabe; ssp() n’est pas pertinente ici, puisque toutes les syllabes du portugais respectent le SSP.
example = tibble(word = c("partolo", "metrilpo", "vanplidos"))
example = example |>
rowwise() |>
mutate(ipa = ipa(word),
syl2 = getSyl(word = ipa, pos = 2),
demi1 = demi(word = syl2, d = 1),
disp = sonDisp(demi = demi1),
SSP = ssp(demi = demi1, d = 1))| word | ipa | syl2 | demi1 | disp | SSP |
|---|---|---|---|---|---|
| partolo | par.ˈto.lo* | to | to | 0.06 | 1 |
| metrilpo | me.ˈtril.po* | tril | tri | 0.56 | 1 |
| vanplidos | vam.ˈpli.dos* | pli | pli | 0.56 | 1 |
Vous pouvez aussi calculer la dispersion moyenne de sonorité pour des mots entiers avec meanSonDisp(). Si les mots qui vous intéressent sont des mots portugais possibles ou réels, vous pouvez les entrer sous leur forme orthographique. Sinon, ils doivent être transcrits phonémiquement et syllabés. Dans ce cas, utilisez phonemic = T.
meanSonDisp(word = c("partolo", "metrilpo", "vanplidos"))
#> [1] 0.19Visualisation de la sonorité
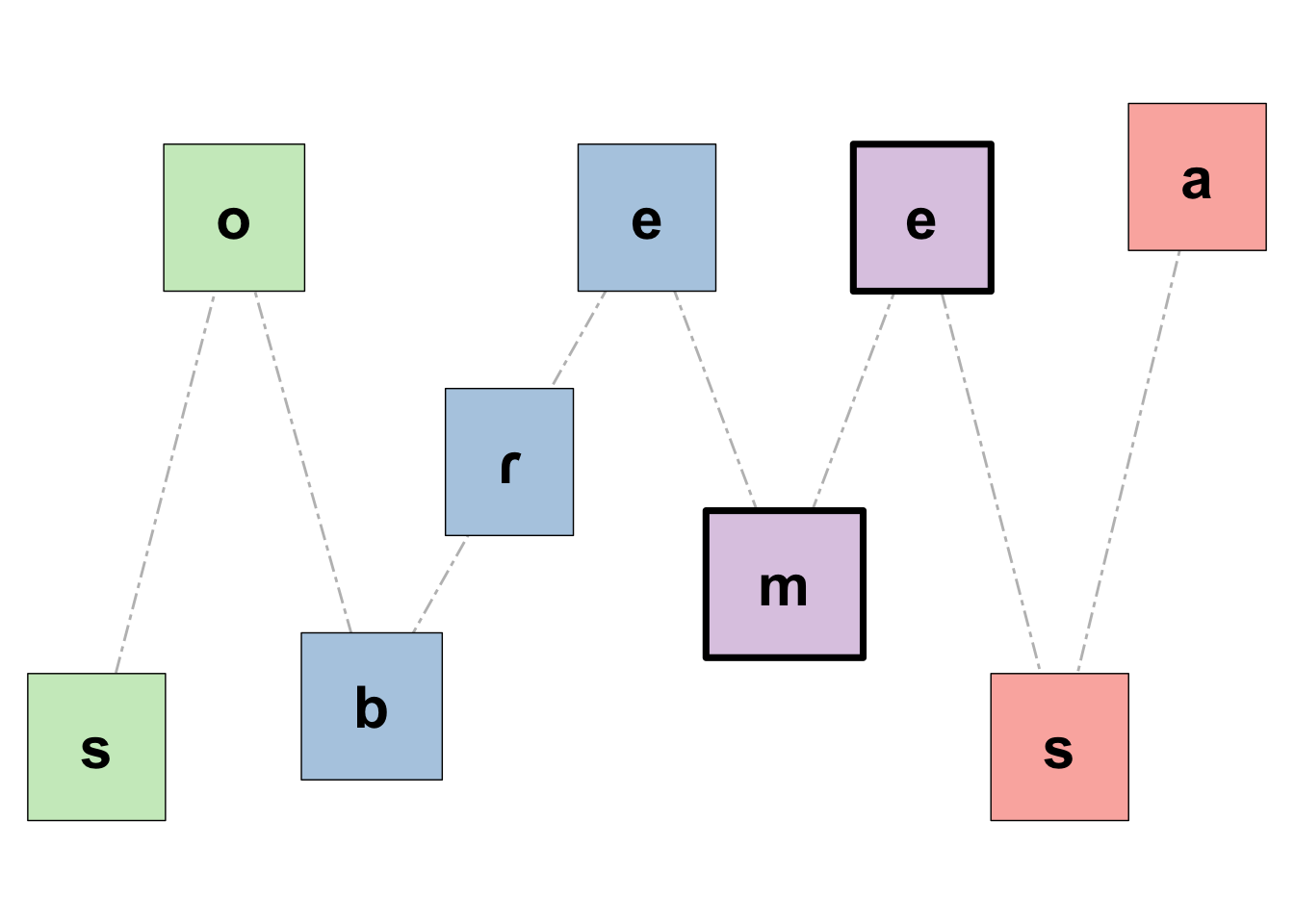
La fonction plotSon() crée une figure avec ggplot2 pour visualiser le profil de sonorité d’un mot donné, qui doit être phonémiquement transcrit. Cette fonction est adaptée de l’application Shiny que vous trouverez ici. Si vous voulez que la figure différencie les syllabes du mot (syl = T), l’entrée doit aussi être syllabée; dans ce cas, la syllabe accentuée sera mise en évidence avec des bordures plus épaisses. Enfin, si vous voulez enregistrer votre figure, ajoutez simplement save_plot = T à la fonction. La fonction accepte un inventaire phonémique relativement flexible. Si un phonème n’est pas pris en charge, la fonction l’affichera (et la figure ne sera pas générée). L’échelle de sonorité utilisée ici est décrite dans Parker (2011).
"combradol" |>
ipa() |>
plotSon(syl = F)
"sobremesa" |>
ipa(lg = "sp") |>
plotSon(syl = T)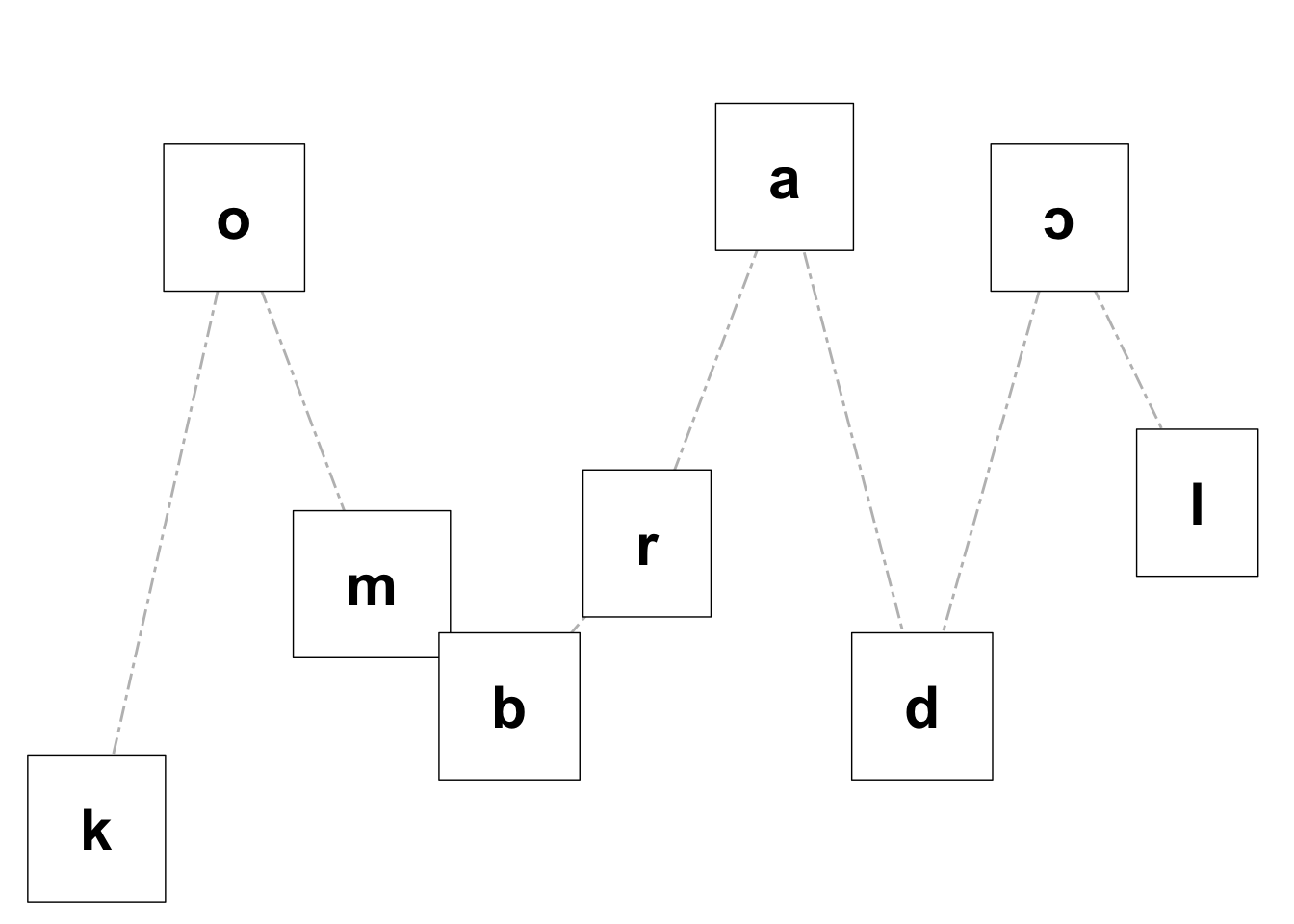
Probabilités de bigrammes
La fonction biGram_pt() renvoie la probabilité logarithmique d’un mot portugais possible (word doit être transcrit largement). La chaîne doit utiliser une transcription phonémique large, sans syllabation ni accent. La référence utilisée pour calculer les probabilités est le Portuguese Stress Lexicon.
biGram_pt("paklode")
#> [1] -43.11171Deux fonctions supplémentaires peuvent être utilisées pour explorer les bigrammes : nGramTbl() génère un tibble de bigrammes phonotactiques à partir d’un texte donné, et plotnGrams() crée une figure pour les entrées générées avec nGramTbl(). Consultez ?plotnGrams() pour plus d’informations.
Générateur de mots en portugais
La fonction wug_pt() génère un mot hypothétique en portugais. Cette fonction est surtout conçue pour vous aider à démarrer la création de mots fictifs. Vous voudrez probablement ajuster les résultats en fonction de vos préférences phonotactiques. La fonction tient déjà compte de certains effets de l’OCP et interdit plus d’un groupe consonantique d’attaque par mot, puisque cela reste relativement rare en portugais. Cela dit, certaines séquences paraîtront encore moins naturelles. La fonction n’est pas trop restrictive, justement parce que vous pouvez viser un large éventail de variables en créant des mots nouveaux. Enfin, si vous souhaitez inclure la palatalisation, définissez palatalization = T; dans ce cas, biGram_pt() dépalatalisera les mots pour son calcul, puisqu’il repose sur une transcription phonémique.
set.seed(1)
wug_pt(profile = "LHL")
#> [1] "dra.ˈbur.me"# Créons un tableau avec 5 mots fictifs
# et leurs probabilités de bigrammes
set.seed(1)
tibble(word = character(5)) |>
mutate(word = wug_pt("LHL", n = 5),
bigram = word |>
biGram_pt())| word | bigram |
|---|---|
| dra.ˈbur.me | -118.61127 |
| ze.ˈfran.ka | -85.59775 |
| be.ˈʒan.tre | -84.75405 |
| ʒa.ˈgran.fe | -87.60279 |
| me.ˈxes.vro | -100.89858 |
Visualisation des voyelles
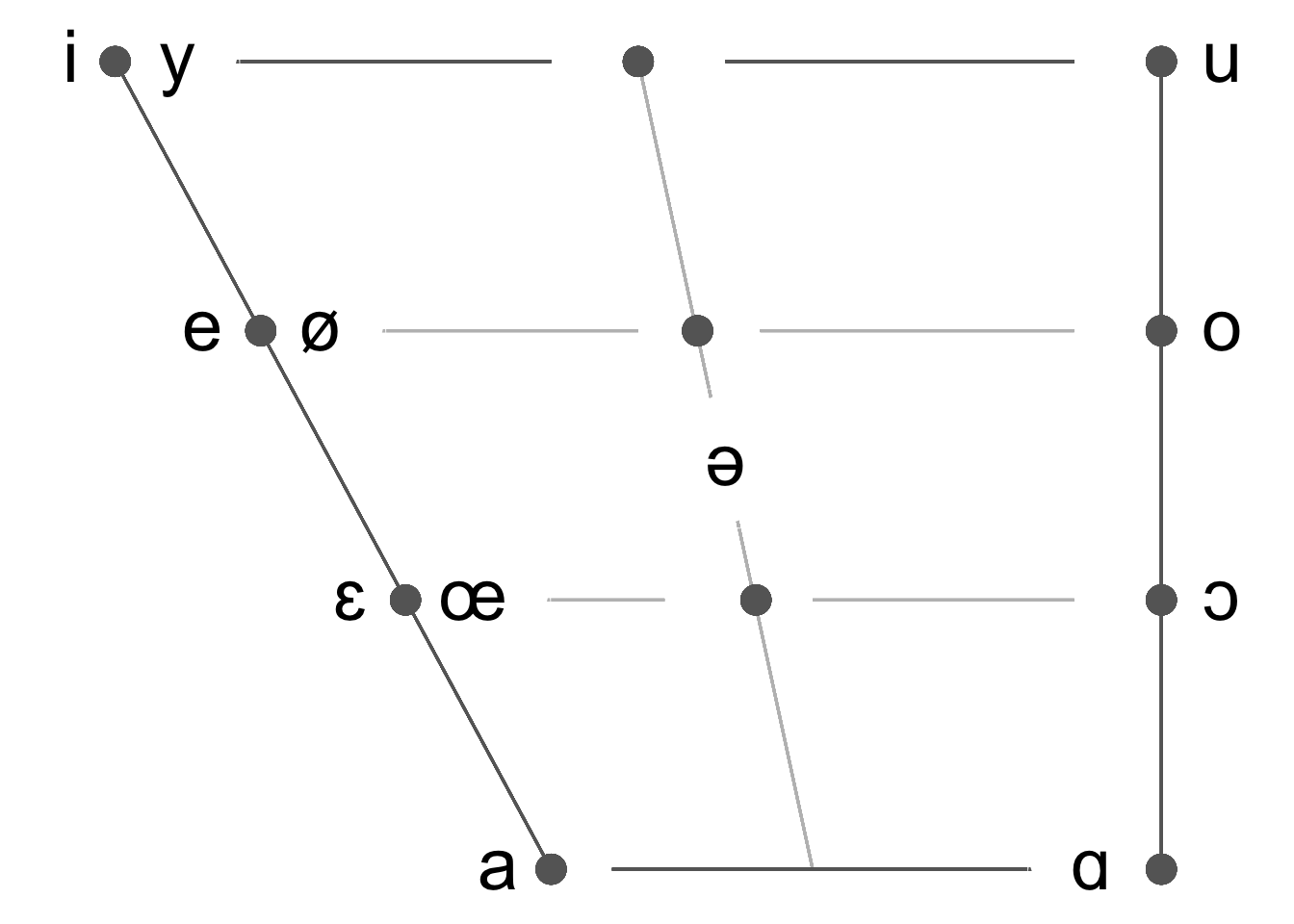
La fonction plotVowels() crée un trapèze vocalique avec ggplot2. Si tex = T, la fonction enregistre aussi un fichier tex contenant le code LaTeX nécessaire pour produire le même trapèze à l’aide du package vowel. Langues disponibles : arabe, français, anglais, néerlandais, allemand, hindi, italien, japonais, coréen, mandarin, portugais, espagnol, swahili, russe, talian, thaï et vietnamien. Seules les voyelles orales monophthongales sont représentées. Cette fonction existe aussi sous forme d’application Shiny ici.
plotVowels(lg = "Spanish", tex = F)
plotVowels(lg = "French", tex = F)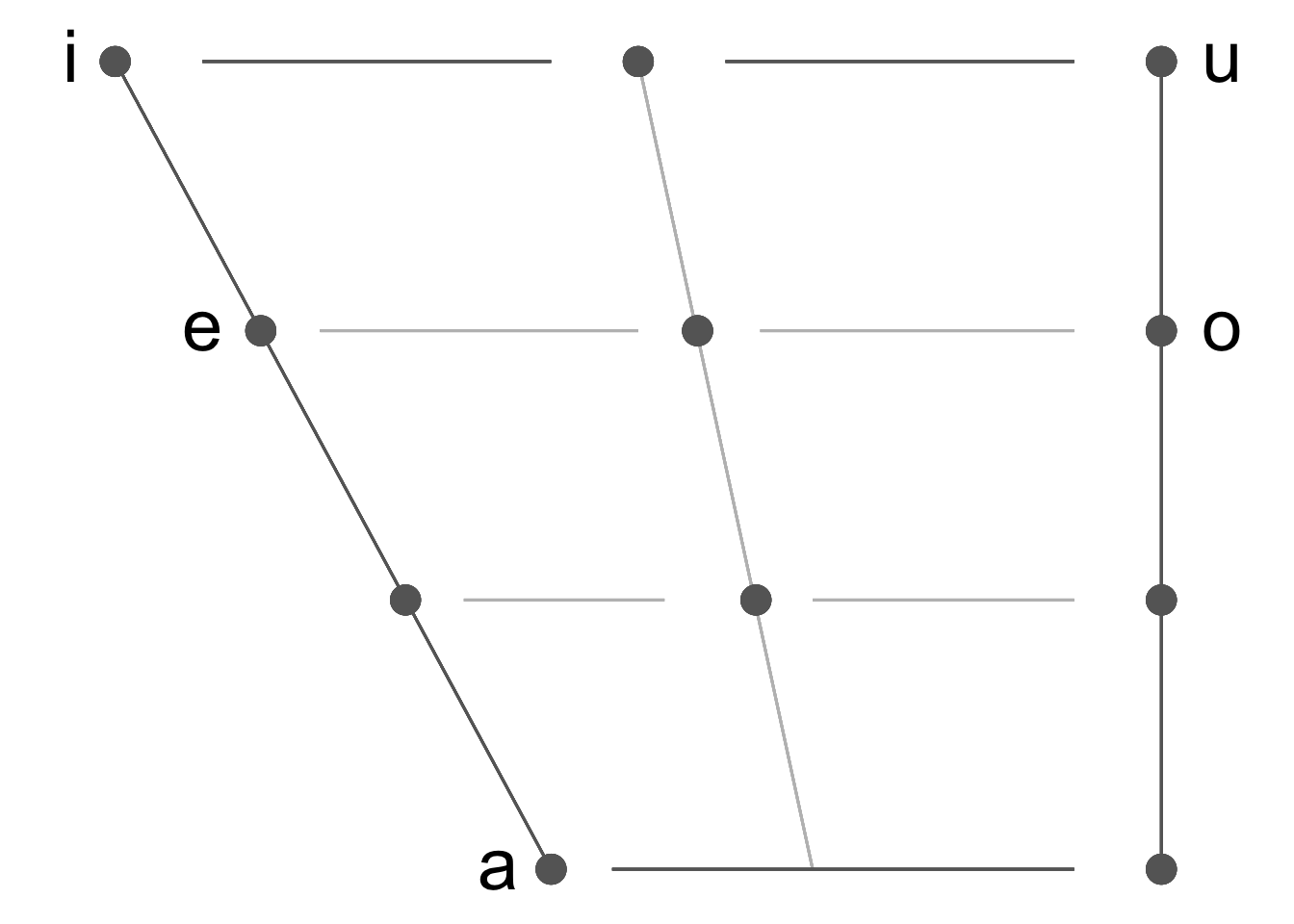
Si vous utilisez Typst, cette fonction a été remplacée par phonokit (fonction #vowels()).
De l’API vers TIPA ou Typst
La fonction ipa2tipa() prend une séquence phonémiquement transcrite et renvoie son équivalent en tipa, ce qui peut être pratique si vous utilisez \(\LaTeX\). Vous pouvez aussi utiliser ipa2typst(), qui renvoie une chaîne destinée à être utilisée avec la fonction #ipa() de phonokit.
"Aqui estão algumas palavras" |>
cleanText() |>
ipa(narrow = T) |>
ipa2tipa()
#> Done! Here's your tex code using TIPA:
#> \textipa{ / a."ki es."t\~{a}\~{w} aw."g\~{u}.mas pa."la.vRas / }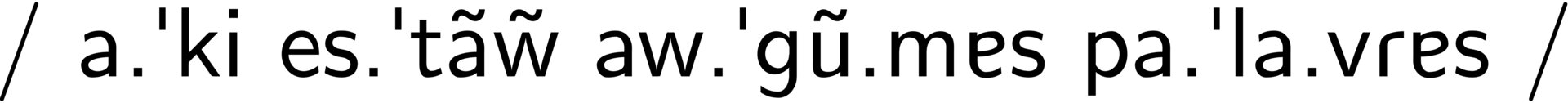
Travailler avec l’âge dans les études d’acquisition
Il est très courant d’utiliser le format aa;mm pour représenter l’âge des enfants dans les études d’acquisition du langage. Pour faciliter le travail avec ce format, deux fonctions ont été ajoutées au package : monthsAge(), qui renvoie un âge en mois à partir d’un âge au format aa;mm, et meanAge(), qui renvoie l’âge moyen d’un vecteur utilisant ce même format (dans les deux fonctions, vous pouvez préciser le séparateur année-mois). Voici quelques exemples :
monthsAge(age = "02;06")
#> [1] 30
monthsAge(age = "05:03", sep = ":")
#> [1] 63
meanAge(age = c("02;06", "03;04", NA))
#> [1] "2;11"
meanAge(age = c("05:03", "04:07"), sep = ":")
#> [1] "4:11"Remerciements et financement
Certaines parties de ce projet ont bénéficié du programme ENVOL de l’Université Laval ainsi que du Conseil de recherches en sciences humaines du Canada (CRSH). Plusieurs auxiliaires de recherche de premier cycle à l’Université Laval ont travaillé sur les fonctions de conversion graphème-phonème pour l’espagnol et le français : Nicolas C. Bustos, Emmy Dumont et Linda Wong. Matéo Levesque a mis en œuvre des expressions régulières détaillées pour la transcription du français. Les données de consultation françaises sont dérivées de Lexique 4 (New et al., 2026), distribué par OpenLexicon sous licence CC BY-SA 4.0. Les données de consultation italiennes et espagnoles sont dérivées du Wiktionnaire anglais via Wiktextract, telles que distribuées par kaikki.org; le contenu du Wiktionnaire est disponible sous licence CC BY-SA. Les données anglaises sont dérivées du CMU Pronouncing Dictionary.
Citer le package
citation("Fonology")
#> To cite Fonology in publications, use:
#>
#> Garcia, Guilherme D. (2026). Fonology: Phonological Analysis in R. R
#> package version 1.2.0 (first published 2023, latest 2026). Available
#> at https://gdgarcia.ca/fonology
#>
#> A BibTeX entry for LaTeX users is
#>
#> @Manual{,
#> title = {Fonology: Phonological Analysis in {R}},
#> author = {Guilherme D. Garcia},
#> note = {R package version 1.2.0 (first published 2023, latest 2026)},
#> year = {2026},
#> url = {https://gdgarcia.ca/fonology},
#> }Copyright © Guilherme Duarte Garcia
Les références
Clements, G. N. (1990). The role of the sonority cycle in core syllabification. In J. Kingston & M. Beckman (Éds.), Papers in Laboratory phonology 1: Between the grammar and physics of speech (p. 283‑333). Cambridge University Press.
Garcia, G. D. (2026). Fonology: Phonological Analysis in R. https://doi.org/10.5281/zenodo.19958335
Goldwater, S., & Johnson, M. (2003). Learning OT constraint rankings using a Maximum Entropy model. Proceedings of the Stockholm Workshop on Variation within Optimality Theory, 111‑120.
Hayes, B., & Wilson, C. (2008). A Maximum Entropy Model of Phonotactics and Phonotactic Learning. Linguistic Inquiry, 39(3), 379‑440. https://doi.org/10.1162/ling.2008.39.3.379
Mayer, C., Tan, A., & Zuraw, K. R. (2024). Introducing
maxent.ot: An R package for Maximum Entropy constraint grammars. Phonological Data and Analysis, 6(4), 1‑44. https://doi.org/10.3765/pda.v6art4.88
New, B., Pallier, C., Schalchli, G., Bourgin, J., & Gimenes, M. (2026). Lexique 4: A major upgrade of the Lexique French lexical database. Behavior Research Methods. http://www.lexique.org/databases/Lexique400/Lexique400.pdf
Parker, S. (2011). Sonority. In M. van Oostendorp, C. J. Ewen, E. Hume, & K. Rice (Éds.), The Blackwell Companion to Phonology (p. 1160‑1184). Wiley Online Library. https://doi.org/10.1002/9781444335262.wbctp0049
Wijffels, J. (2023). udpipe: Tokenization, Parts of Speech Tagging, Lemmatization and Dependency Parsing with the ’UDPipe’ ’NLP’ Toolkit. https://CRAN.R-project.org/package=udpipe
Wilson, C. (2006). Learning phonology with substantive bias: an experimental and computational study of velar palatalization. Cognitive Science, 30(5), 945‑982. https://doi.org/10.1207/s15516709cog0000_89