![]()
![]()
![]()


Dernière mise à jour : July 2026
1 Introduction
Ce manuel présente phonokit et ses fonctions. phonokit est une bibliothèque Typst conçue pour simplifier la création de structures phonologiques tout en maintenant une précision typographique. Typst est un langage de programmation pour la composition typographique — un excellent tutoriel est disponible ici ainsi qu’une série d’introduction sur YouTube ici.
La bibliothèque fournit des fonctions intuitives pour la transcription API, les représentations prosodiques (syllabes, mores, pieds, mots prosodiques, grilles métriques), les profils de sonorité, les tableaux vocaliques API et les tableaux de consonnes, la phonologie autosegmentale, les représentations multi-niveaux, la géométrie des traits, les matrices de traits SPE, les tableaux de la Théorie de l’Optimalité, la Grammaire harmonique, la Grammaire harmonique stochastique, les grammaires à entropie maximale, les diagrammes de Hasse, les exemples linguistiques numérotés et les symboles utilitaires. Les objectifs principaux de phonokit sont de minimiser l’effort et de maximiser la qualité.
Le dépôt GitHub de la bibliothèque se trouve à guilhermegarcia/phonokit. Commentaires, suggestions et signalements de bogues sont bienvenus — veuillez ouvrir un issue dans le dépôt.
1.1 Installation
Les bibliothèques Typst sont chargées avec la fonction #import au début de votre document typ. Remplacez X.X.X par la version souhaitée :
Importation de la bibliothèque (Typst Universe)
#import "@preview/phonokit:X.X.X": *Si vous souhaitez la version la plus récente, téléchargez ou clonez le dépôt et chargez la bibliothèque localement :
Importation locale
#import "phonokit/lib.typ": *Un lien symbolique peut être nécessaire selon la structure de vos fichiers, car Typst restreint les importations aux fichiers situés dans la racine de compilation et ses sous-répertoires.
1.2 Police
Toutes les fonctions de phonokit requièrent la police Charis pour fonctionner comme prévu (SIL International 2025). Depuis la version 0.3.7, l’utilisateur peut définir une police globale à utiliser par la bibliothèque dans l’ensemble du document :
Définir la police
#import "@preview/phonokit:0.5.12": *
#phonokit-init(font: "New Computer Modern") // add to the top of your document2 API
La transcription API est sans doute la fonctionnalité la plus utilisée lors de la composition de documents en phonologie. Typst prend directement en charge l’entrée Unicode ; techniquement, vous pouvez donc taper des symboles API sans package dédié. Cependant, vous préférerez peut-être utiliser un flux de travail basé sur des fonctions, surtout si vous venez de \(\LaTeX\). phonokit l’accomplit avec la fonction #ipa(), qui prend une chaîne de caractères en entrée. La fonction utilise la notation familière de tipa (Rei 1996), à quelques exceptions près (p. ex., l’accent secondaire est représenté par une virgule ,, et non par deux guillemets doubles "").
2.1 Transcription
Les symboles introduits par deux barres obliques inverses \\ ne doivent pas avoir de caractères adjacents. Pour les archiphonèmes, utilisez \\ suivi d’une lettre majuscule. Ainsi, #ipa("N") correspond à ŋ (sa valeur TIPA), tandis que #ipa("\\N") produit un N majuscule — un archiphonème — rendu avec la police de la bibliothèque, ce qui assure la cohérence typographique entre phonèmes et archiphonèmes. Voir les exemples dans Figure 1.

Exemples de transcription API
#ipa("DIs \\s Iz \\s @ \\s sEn.t@ns")
#ipa("N \\N R \\R \\I I Z \\Z")
#ipa("p \\h I k \\* \\s \\t tS \\ae t \\s p \\r l iz")Vous pouvez télécharger la fiche de référence en tant que fichier autonome ici.
2.2 Consonnes
Deux fonctions supplémentaires permettent aux utilisateurs de créer rapidement des tableaux de consonnes et des trapèzes vocaliques à partir d’une chaîne de phonèmes. La fonction #consonants() reproduit le tableau des consonnes pulmoniques du tableau API avec quelques modifications mineures. Par exemple, les affriquées sont affichées avec affricates: true, et l’argument abbreviate: true abrège les étiquettes des lignes et colonnes. Figure 2 montre l’inventaire consonantique de l’italien.
Tableau de consonnes (italien)
#consonants("italian", affricates: true, abbreviate: true)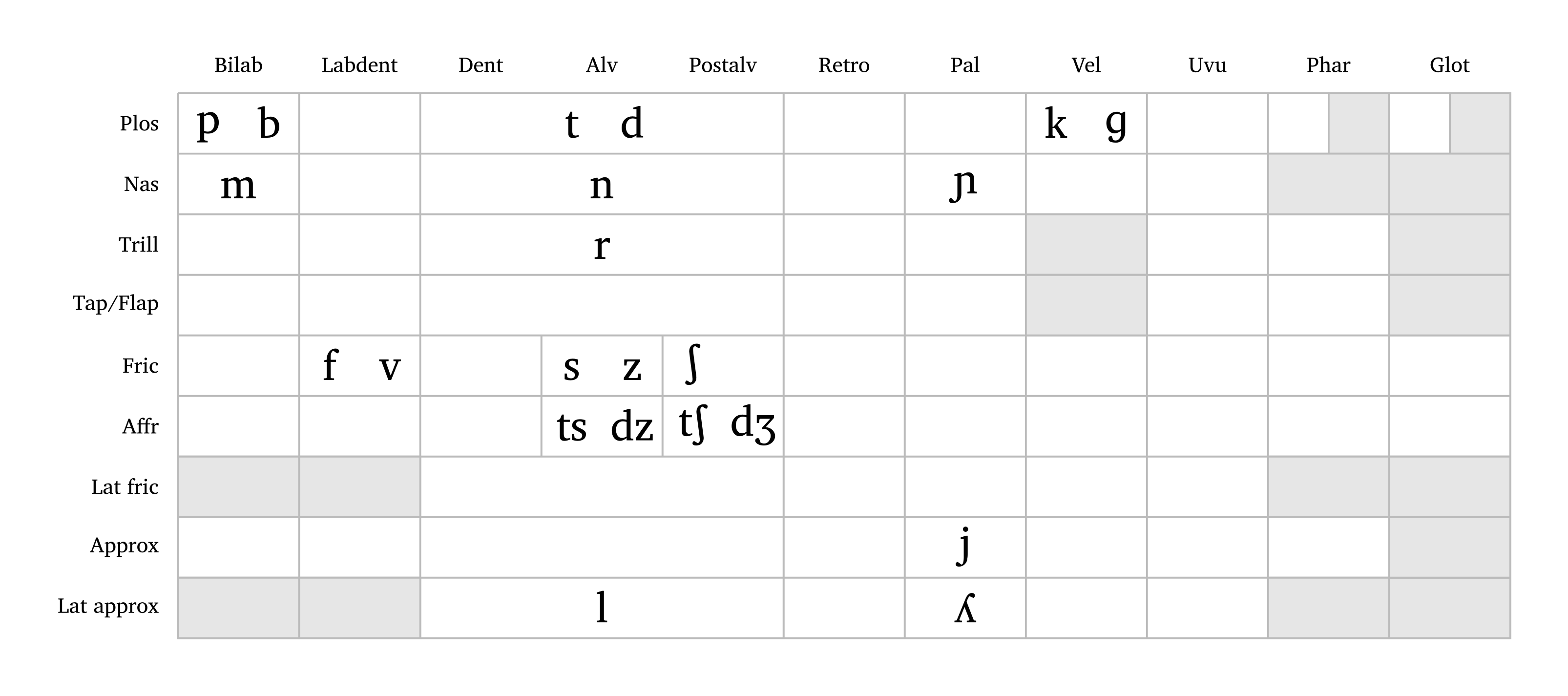
L’utilisateur peut saisir un nom de langue (Arabic, English, French, German, Italian, Japanese, Portuguese, Russian, Spanish — tous en minuscules ; aussi all pour toutes les consonnes) ou une chaîne de consonnes pour créer un inventaire personnalisé. Les consonnes personnalisées suivent le même format d’entrée que #ipa(). Les affriquées et les consonnes aspirées nécessitent des accolades et les arguments affricates: true et aspirated: true, comme le montre la légende de Figure 3. La fonction prend également en charge le redimensionnement flexible avec l’argument scale.
Tableau de consonnes personnalisé
#consonants("ts{ts}psS \\*r g{tS} {k \\h}", affricates: true, aspirated: true)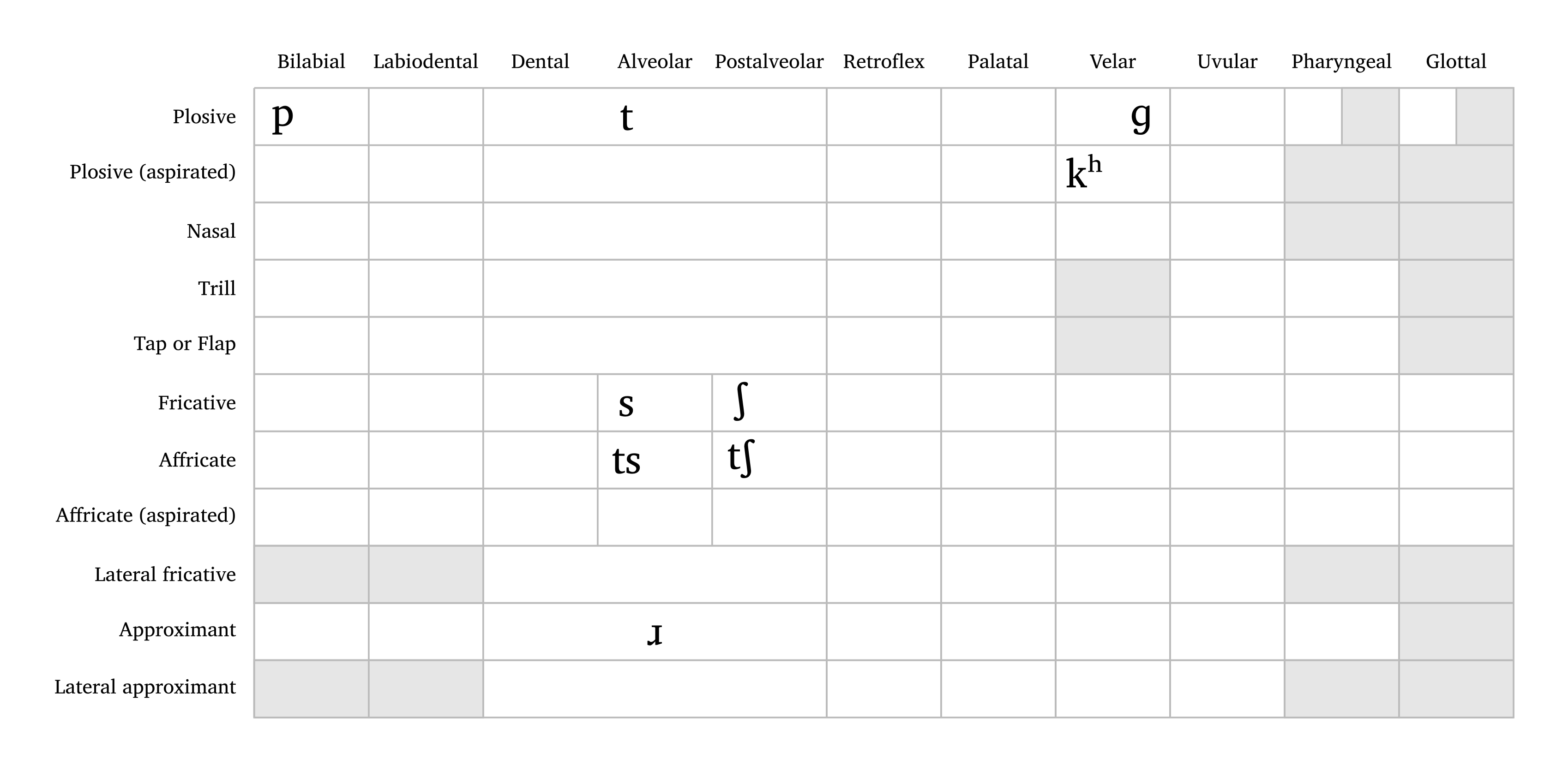
2.3 Voyelles
La fonction #vowels() accepte également une langue prédéfinie ou une chaîne de caractères comme entrée. L’argument scale est également disponible ici, permettant à l’utilisateur d’ajuster la taille du trapèze selon les besoins.
Trapèzes vocaliques
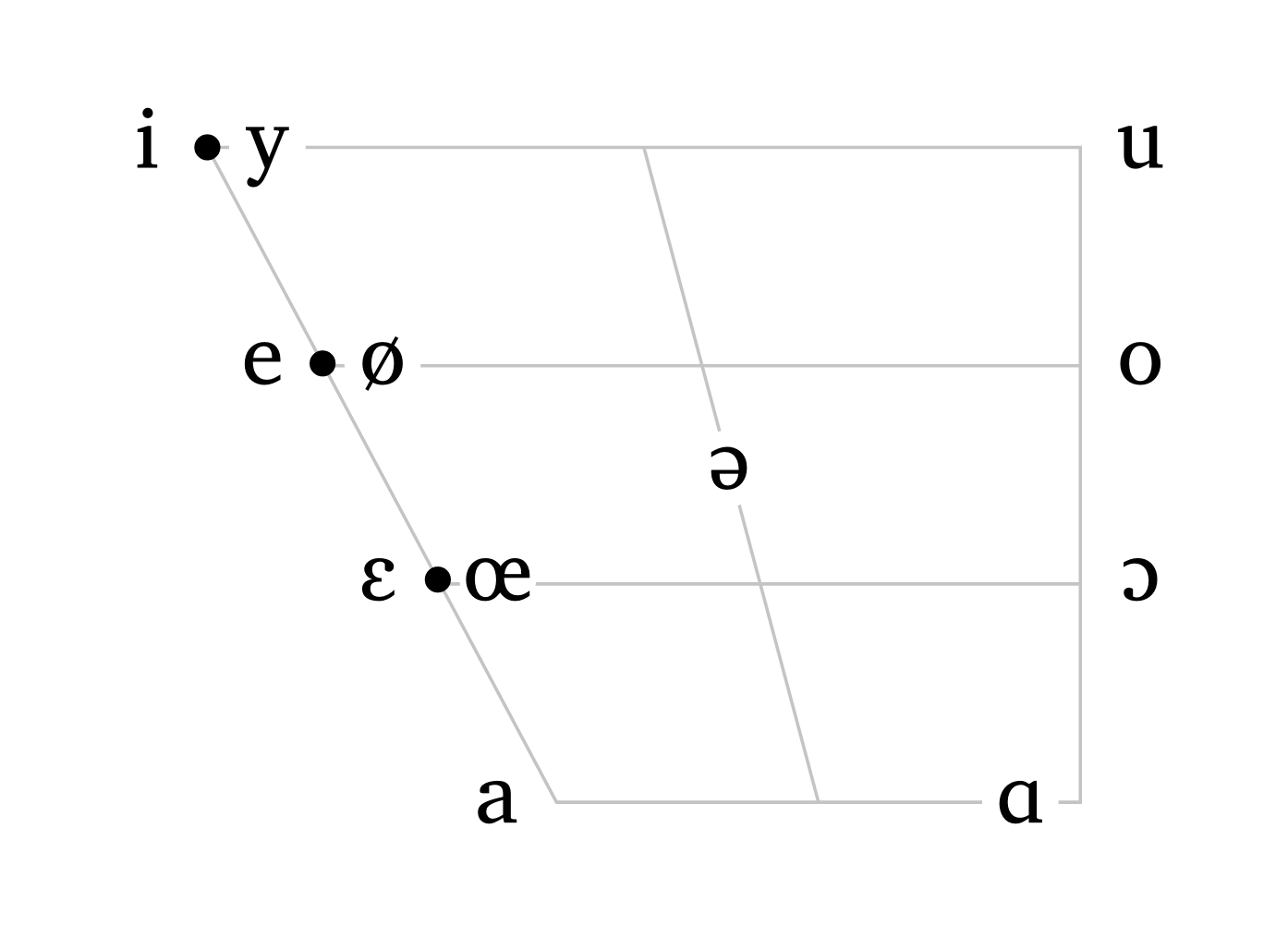
#vowels("english", scale: 0.6)
#vowels("french", scale: 0.6)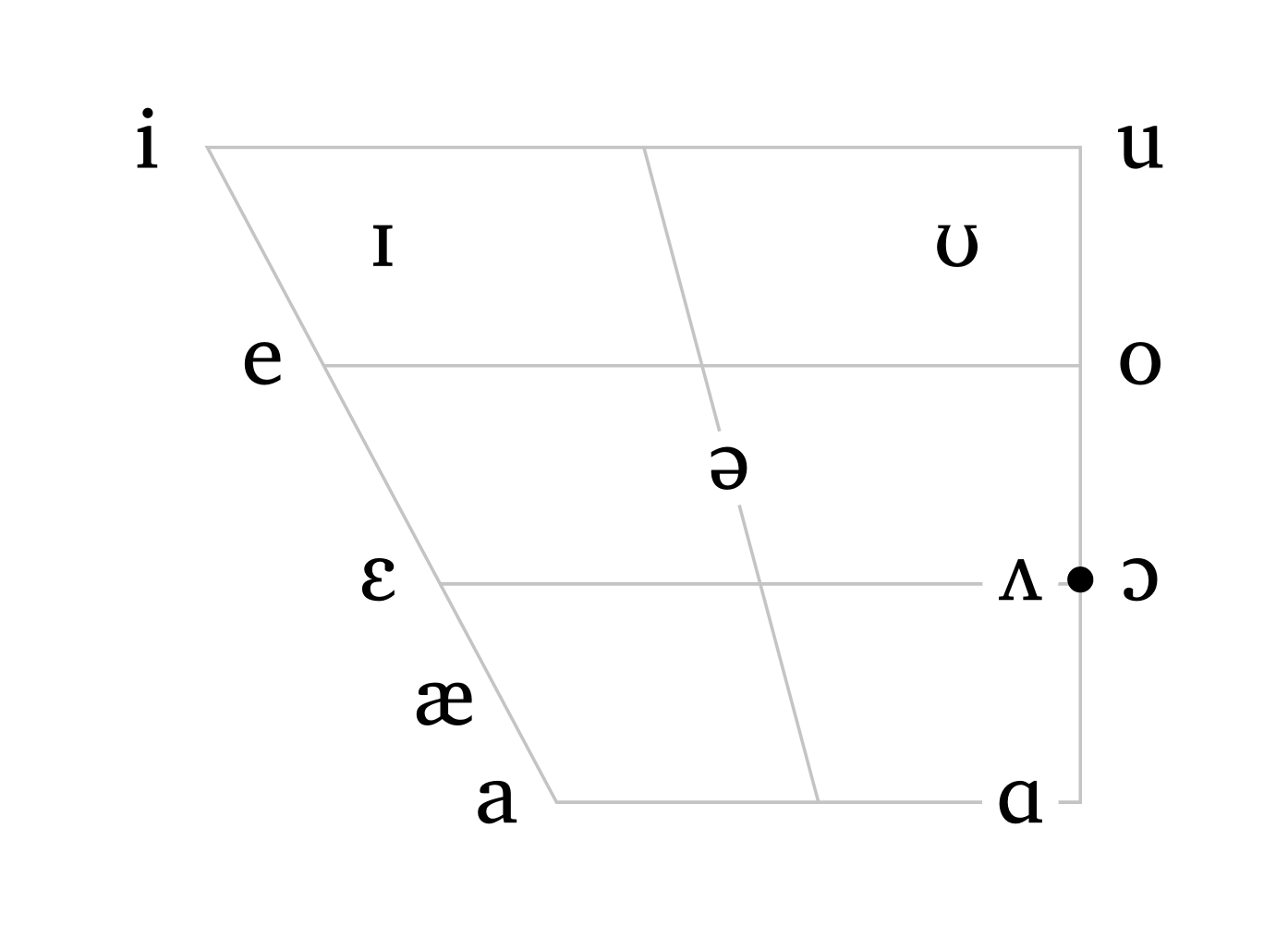
Depuis la version 0.4.5, la fonction #vowels() accepte des arguments optionnels supplémentaires pour inclure des flèches, des voyelles décalées et des surlignages. Figure 6 illustre comment arrows et highlight peuvent être utilisés pour afficher les diphtongues en anglais nord-américain. Les flèches peuvent être courbées (curved: true) ou en pointillés (arrow-style: "dashed"), et les couleurs peuvent être ajustées avec arrow-color et highlight-color.
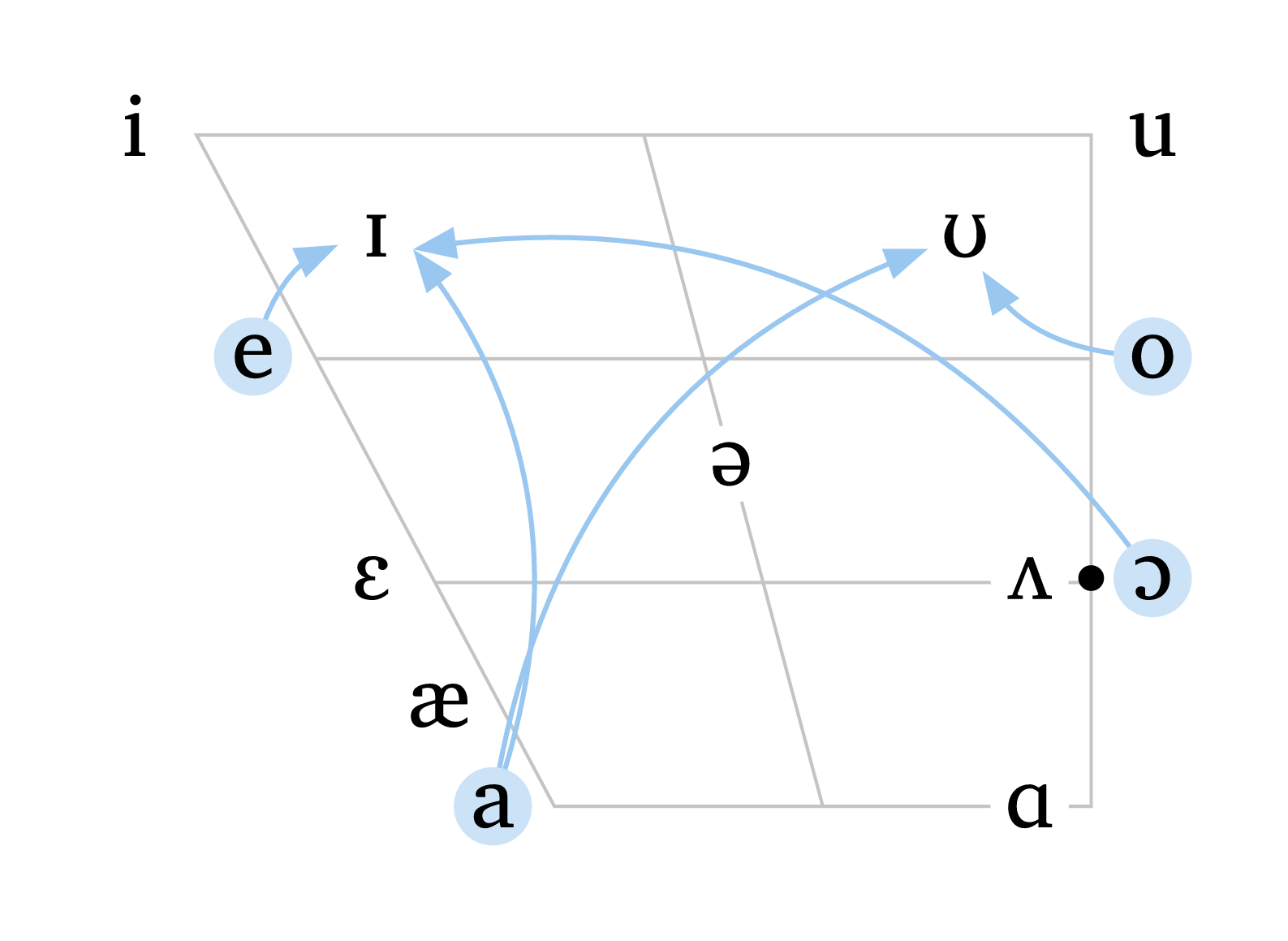
Voyelles avec flèches et surlignages
#vowels(
"english",
arrows: (
("a", "U"),
("a", "I"),
("e", "I"),
("O", "I"),
("o", "U"),
),
arrow-color: blue.lighten(60%),
curved: true,
highlight: ("a", "e", "o", "O"),
highlight-color: blue.lighten(80%),
)L’argument shift permet de spécifier une voyelle et un décalage depuis sa position d’origine, offrant une bien plus grande flexibilité pour illustrer la variation dialectale. Les voyelles décalées peuvent être ciblées indépendamment par highlight, et les flèches peuvent cibler des voyelles décalées en utilisant les mêmes valeurs de décalage. La couleur et la taille des voyelles décalées peuvent être ajustées avec shift-color et shift-size. Figure 7 illustre les flèches, les voyelles décalées, et l’option de supprimer les lignes de grille (rows: 0 et cols: 0).
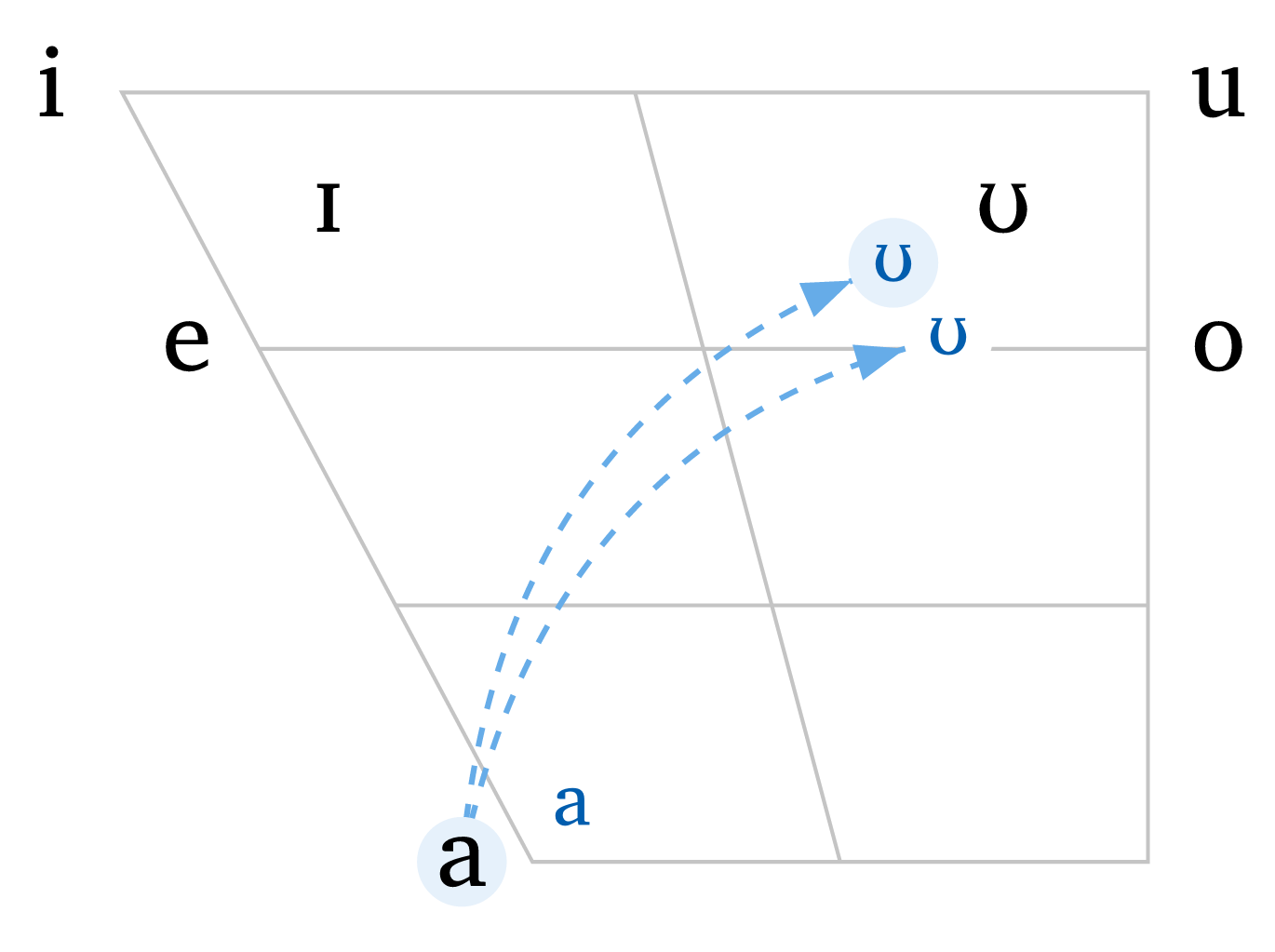
Voyelles avec décalage
#vowels(
"aeiouIU",
arrows: (
("a", ("U", -0.6, -0.3)),
("a", ("U", -0.3, -0.7)),
),
arrow-color: blue.lighten(40%),
arrow-style: "dashed",
curved: true,
shift: (
("a", 0.6, 0.3),
("U", -0.6, -0.3),
("U", -0.3, -0.7),
),
shift-size: 1.5em,
shift-color: blue.darken(20%),
highlight: ("a", ("U", -0.6, -0.3)),
highlight-color: blue.lighten(90%),
)3 SPE
Les règles de réécriture peuvent être complexes, et phonokit fournit deux fonctions primitives pour les matrices de traits qui peuvent être combinées pour former des règles SPE (Chomsky et Halle 1968).
La première fonction est #feat-matrix(), qui produit la matrice de traits maximale pour un phonème donné (avec l’option pour les valeurs 0 si all: true). Cela peut être utile dans les cours d’introduction à la notion de traits distinctifs. La fonction est basée sur les traits de Hayes (2009). Figure 8 montre les matrices pour les phonèmes de « patchy ».
Matrices de traits
#feat-matrix("p") #feat-matrix("\\ae") #feat-matrix("\\t tS") #feat-matrix("i")
La deuxième fonction, #feat(), crée une matrice à partir d’un ensemble de traits — c’est la fonction utilisée dans une règle de réécriture. La notation alpha requiert une syntaxe spécifique : X + "feat" ou X + [smallcaps("feat")]. La fonction utilitaire #blank() ajoute un long soulignement pour le contexte d’application, et #a-r ajoute une flèche droite (autres flèches : #a-l, #a-u, #a-d, #a-lr, #a-ud, #a-sr, #a-sl, #a-r-large). Figure 9 montre une règle d’assimilation du lieu d’articulation nasal.
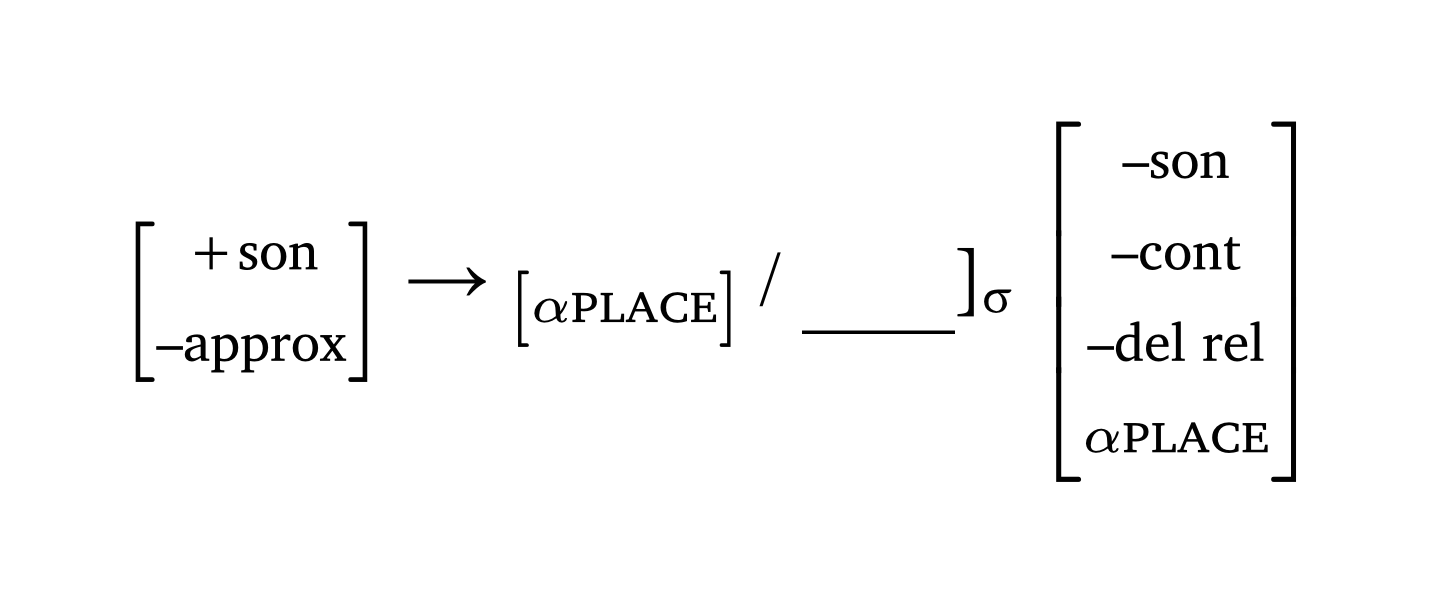
Règle de réécriture SPE
#feat("+son", "–approx") #a-r
#feat(sym.alpha + [#smallcaps("place")]) / #blank()\]#sub[#sym.sigma]
#feat("–son", "–cont", "–del rel", sym.alpha + [#smallcaps("place")])4 Prosodie
4.1 Sonorité
Lors de la discussion du principe de sonorité dans les cours d’introduction, il est utile d’illustrer la sonorité relative avec une représentation visuelle. La fonction #sonority(), basée sur l’échelle de sonorité de Parker (2011, 18), trace les phonèmes et leurs profils de sonorité relatifs. Si des frontières syllabiques sont détectées dans l’entrée, la fonction alterne entre des remplissages blancs et gris pour distinguer chaque syllabe.
Profil de sonorité
#sonority("vA \\*r .sI.ti", scale: 0.7)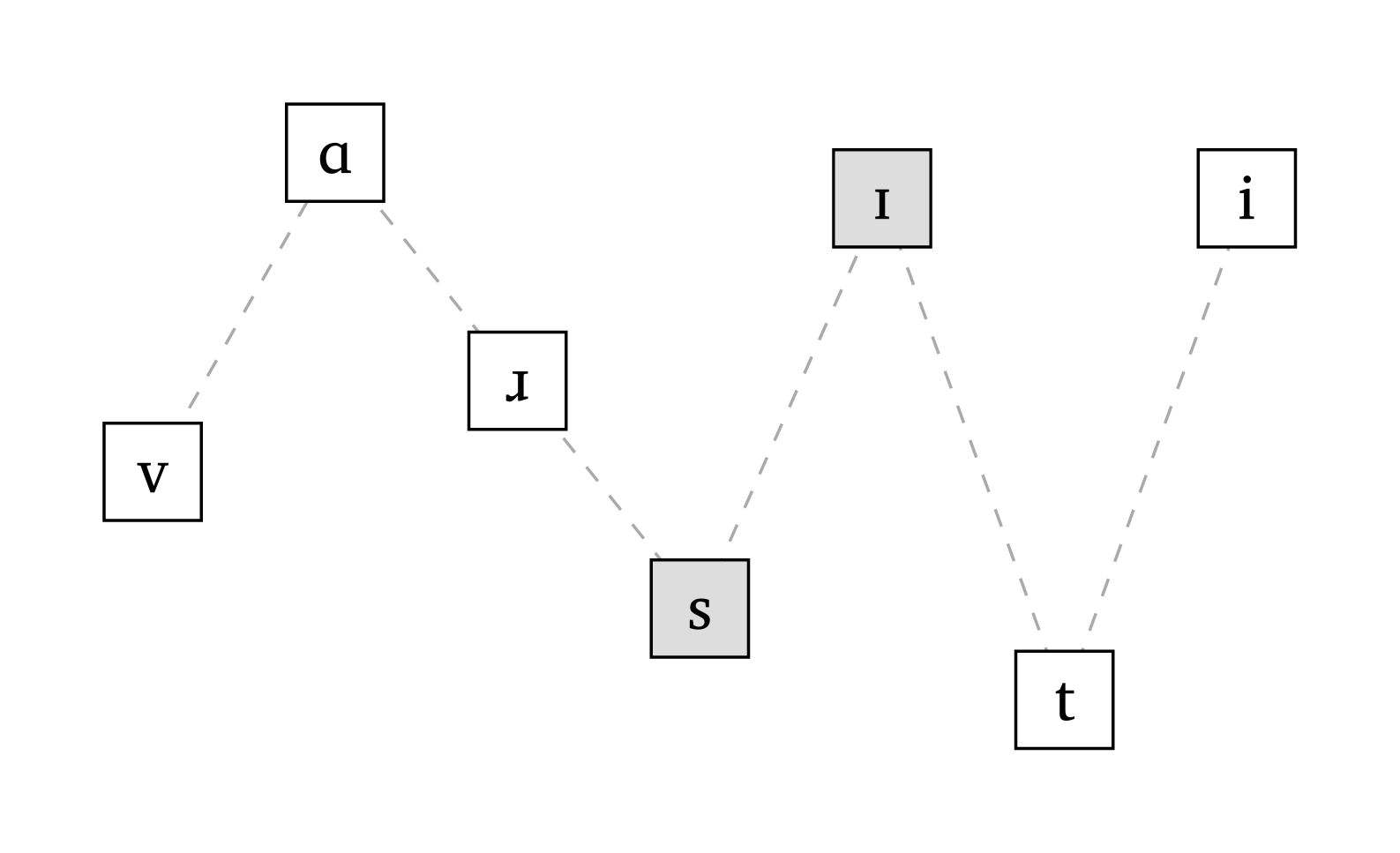
4.2 Syllabes
Deux options sont disponibles : #syllable() pour une représentation attaque-rime classique, et #mora(..., coda: true) pour une représentation moraïque. Cette dernière permet de définir si les codas projettent une more (coda: true). Les deux fonctions sont utilisées uniquement pour les représentations monosyllabiques et acceptent les mêmes conventions d’entrée que #ipa().
Syllabe (attaque-rime)
#syllable("\\t tS \\ae t")Syllabe (moraïque)
#mora("\\t tS \\ae t", coda: true)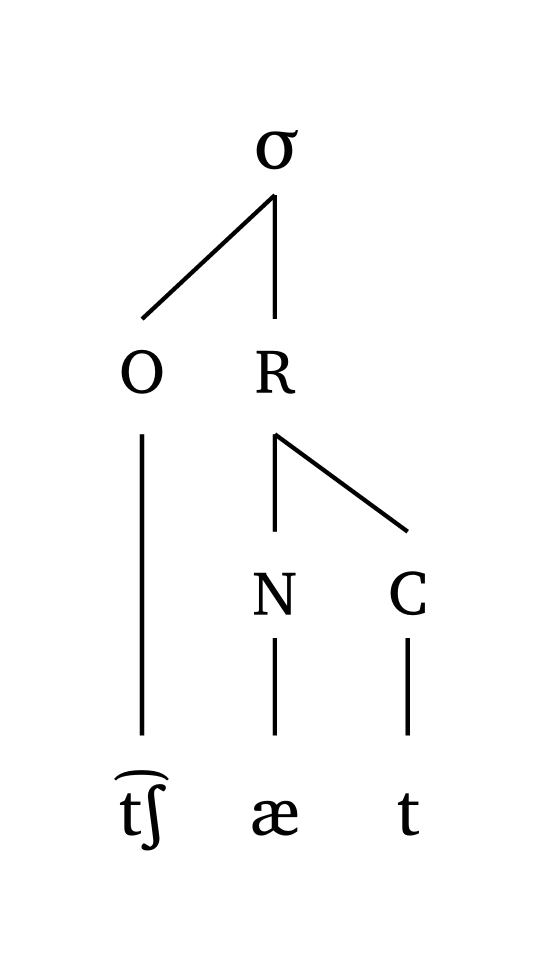
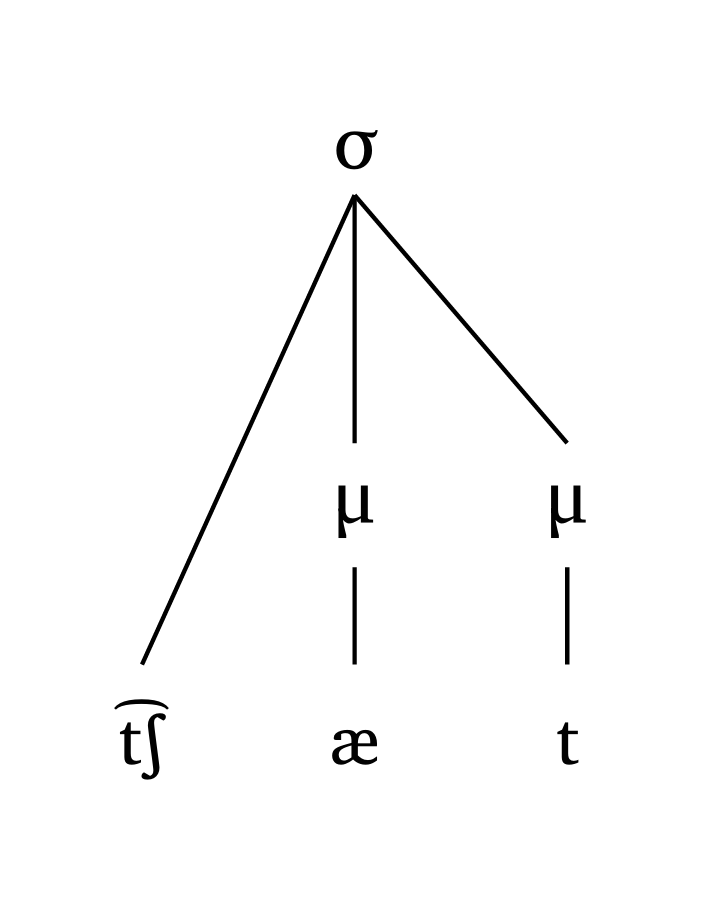
La longueur vocalique est représentée dans #syllable() et #mora() : le caractère : déclenche la marque de longueur, et dans les représentations moraïques, deux mores sont branchées sur la voyelle.
Voyelle longue, attaque-rime
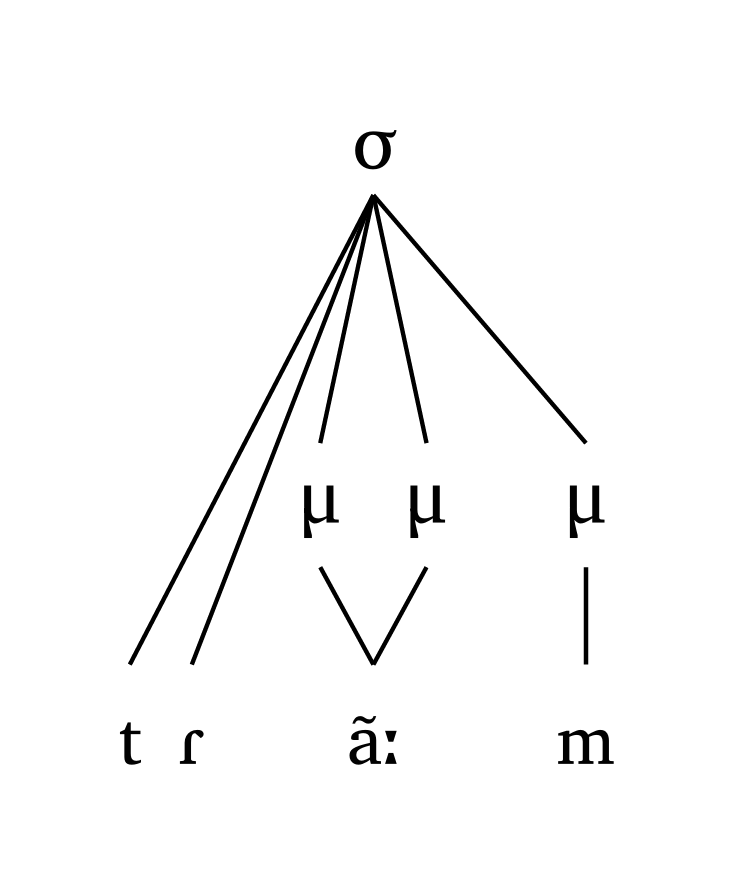
#syllable("tR \\~ a:m")Voyelle longue, moraïque
#mora("tR \\~ a:m", coda: true)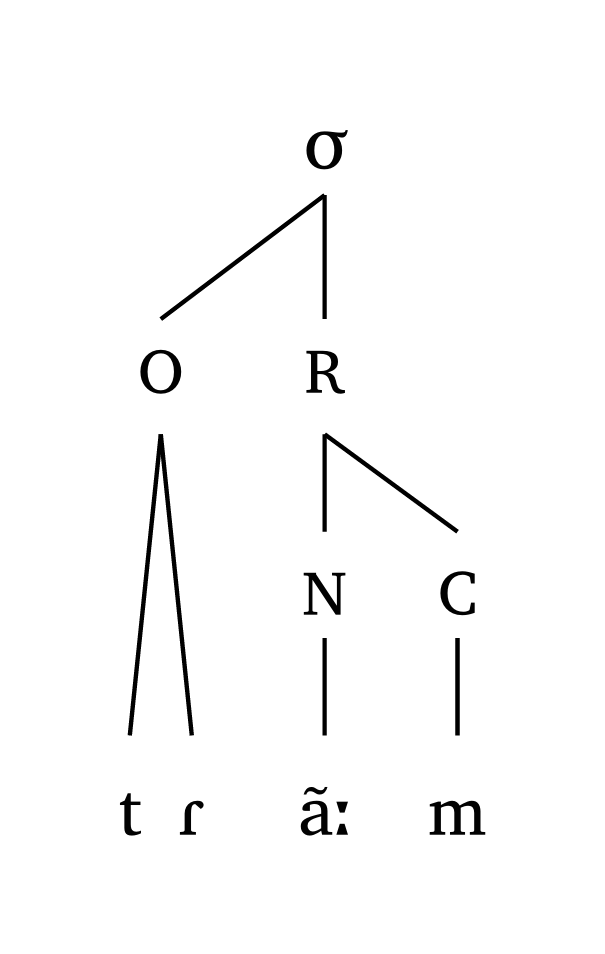
Les dimensions s’ajustent en fonction du nombre de segments trouvés dans l’entrée. Figure 15 illustre cela avec un exemple extrême.
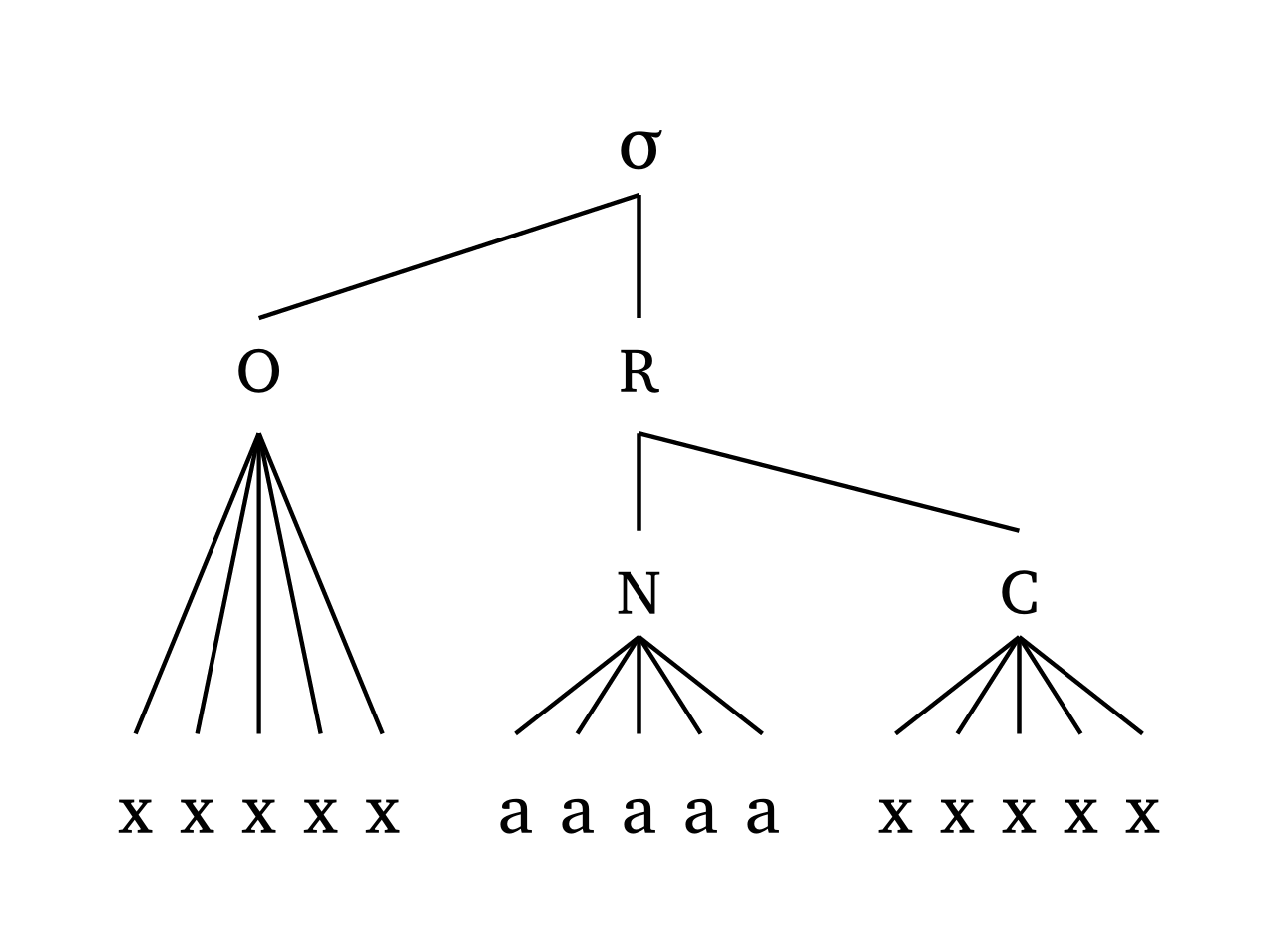
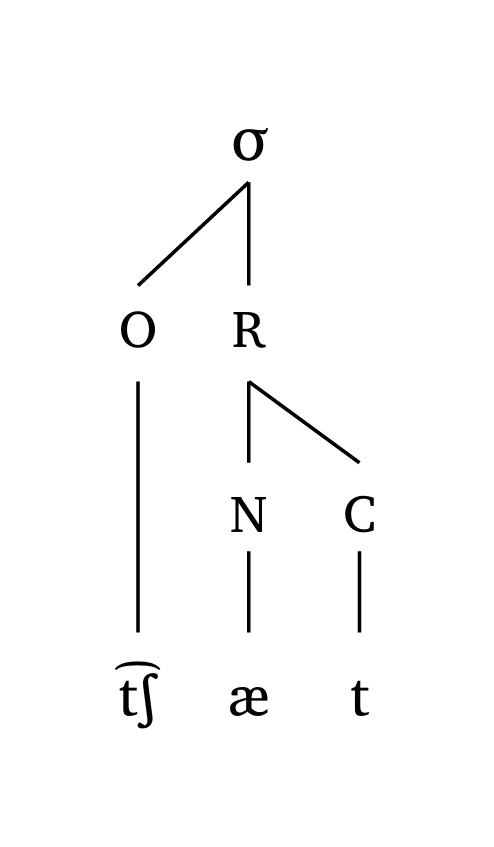
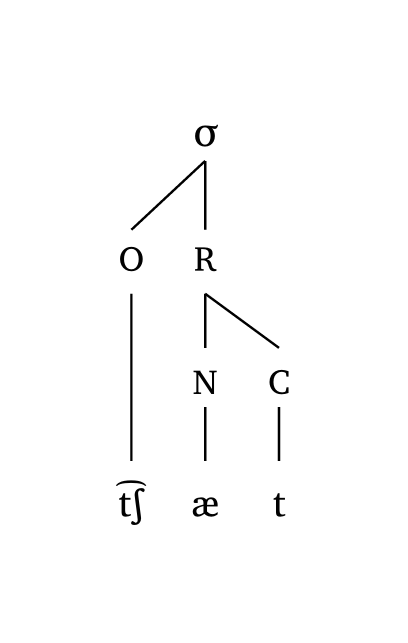
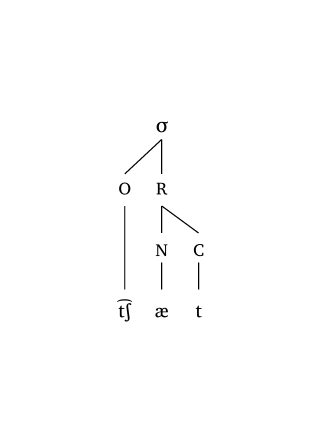
L’argument scale gère uniformément la largeur des lignes et la taille du texte. Figure 16, Figure 17 et Figure 18 montrent des exemples à différents niveaux d’échelle.
4.3 Pieds
Oui. Si vous préférez « Ft » à \(\Sigma\), par exemple, consultez l’annexe Symboles.
Les fonctions #foot() et #foot-mora() représentent un pied unique. Un point . indique la syllabification et une apostrophe ' marque la tête du pied, permettant de créer facilement des trochées et des iambes. Les pieds non binaires (dactyles, etc.) sont également pris en charge.
Trochée
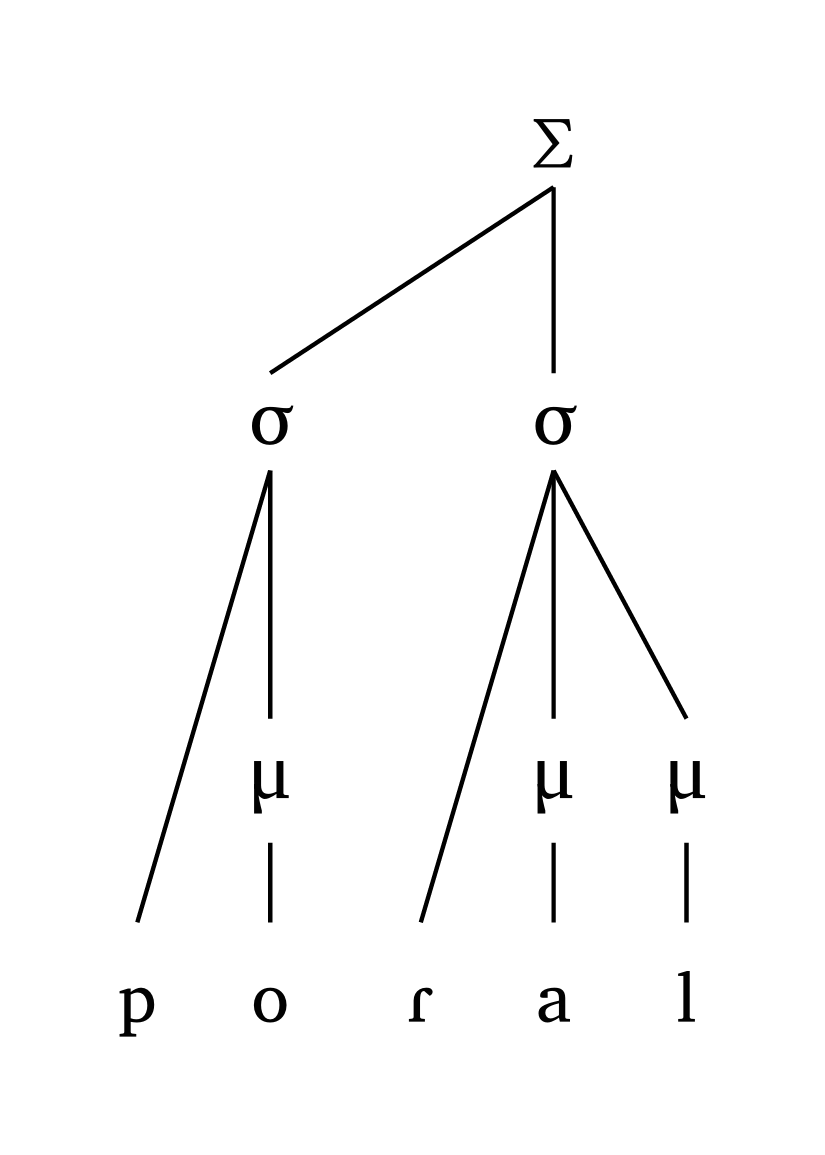
#foot("'p \\h \\ae.\\*r Is")Iambe, moraïque
#foot-mora("po.'Ral", coda: true)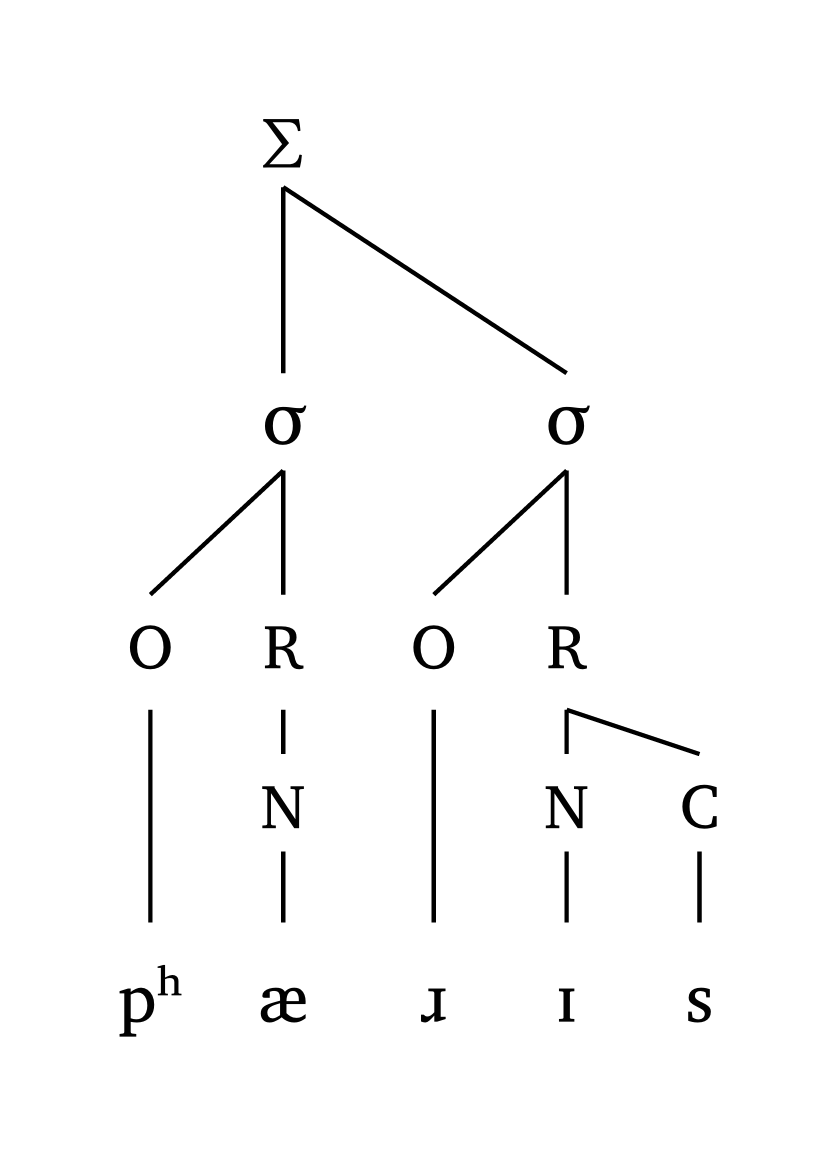
Pied dactylique
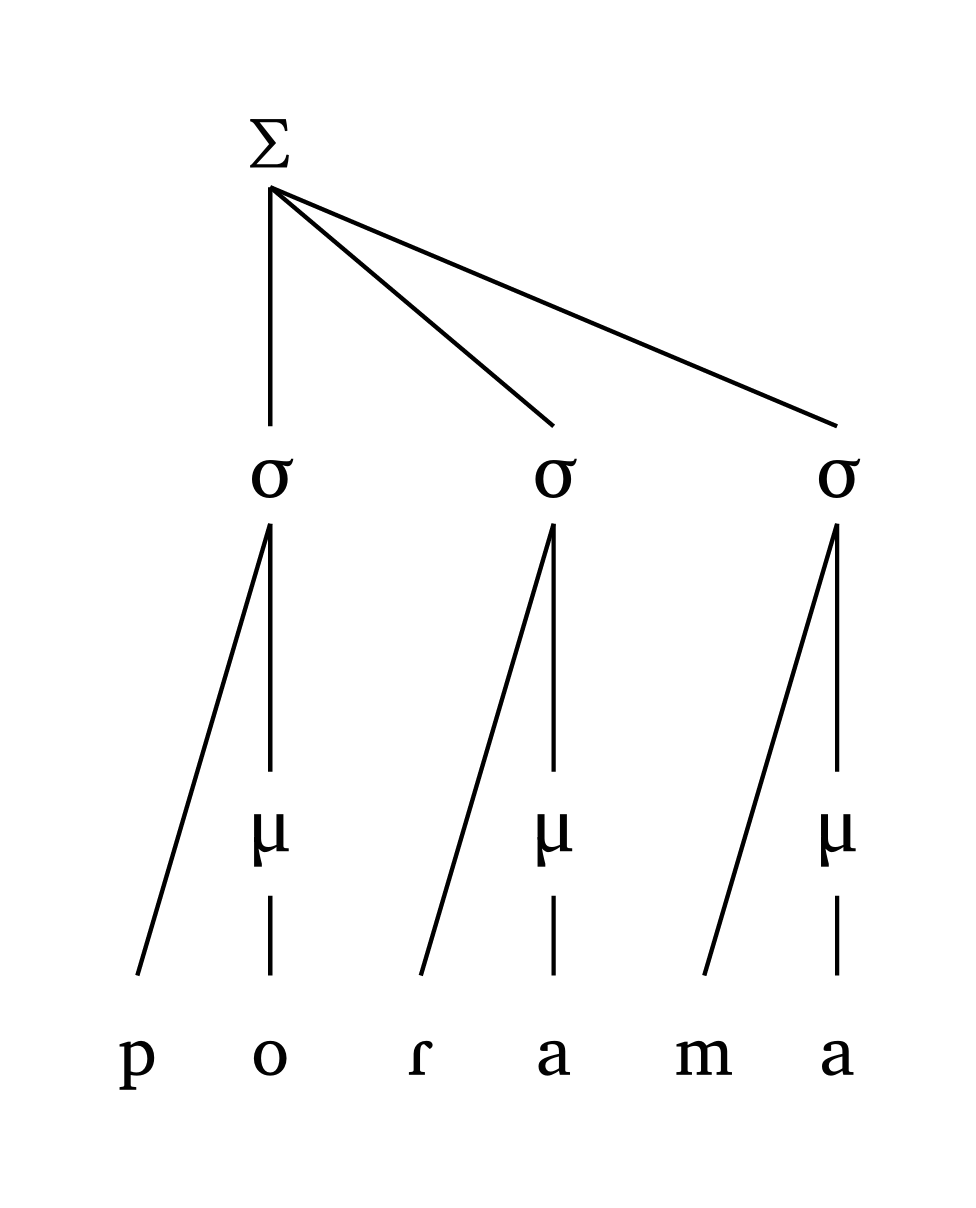
#foot("'po.Ra.ma")Pied dactylique, moraïque
#foot-mora("'po.Ra.ma")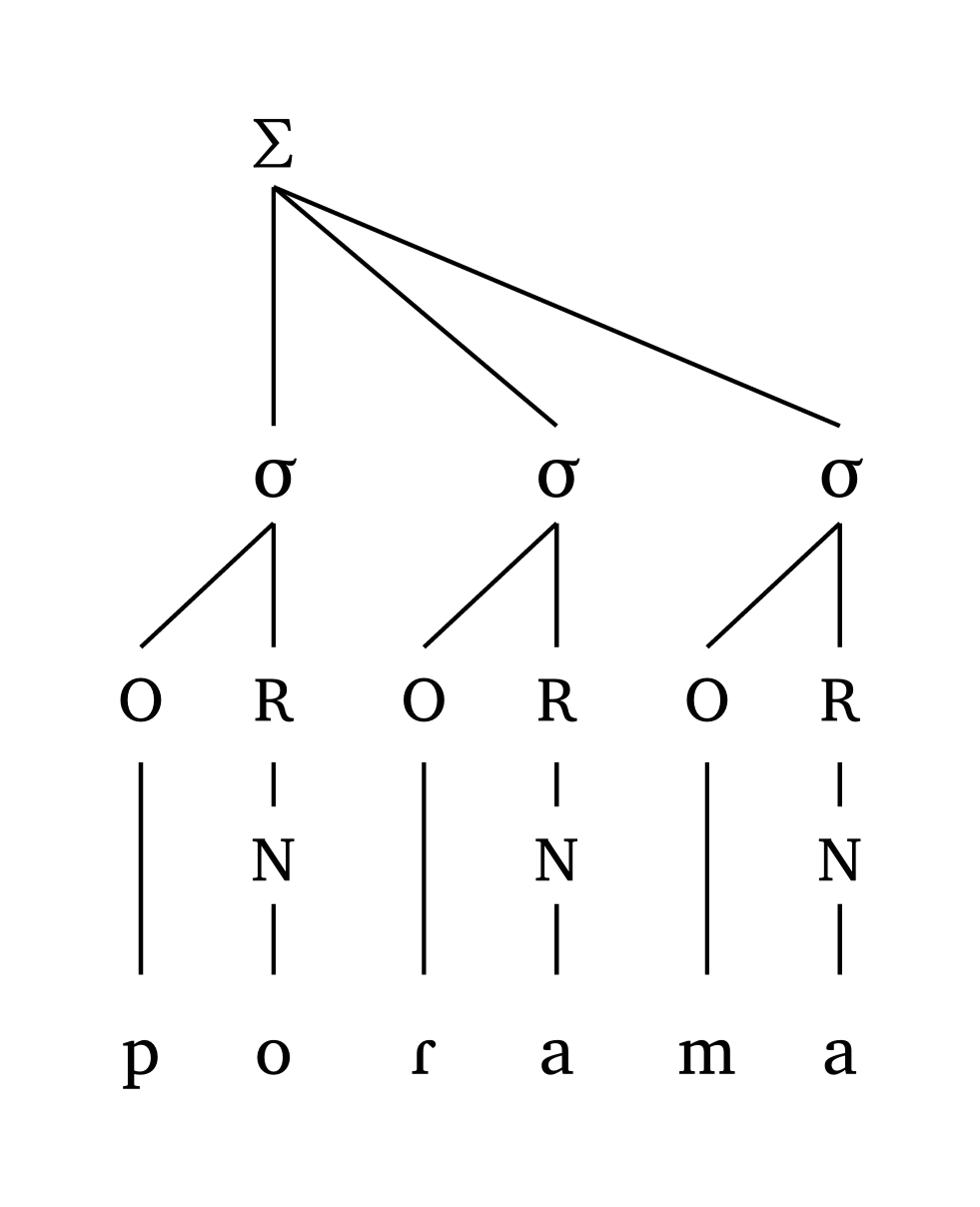
Les géminées sont également représentées. Dans les représentations attaque-rime, une géminée sera liée à la coda et à l’attaque suivante. Dans les représentations moraïques, coda: true fournit la représentation traditionnelle.
Géminée, attaque-rime
#foot("'pot.ta")Géminée, moraïque
#foot-mora("'pot.ta", coda: true)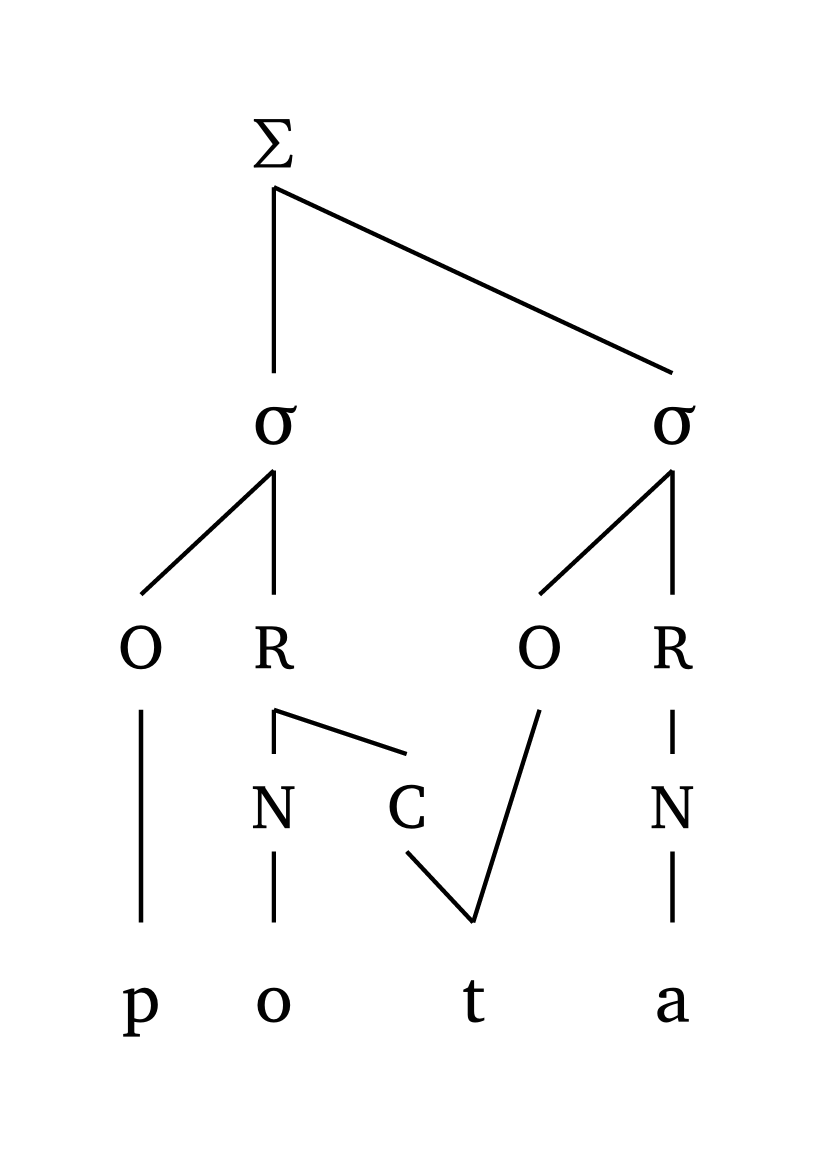
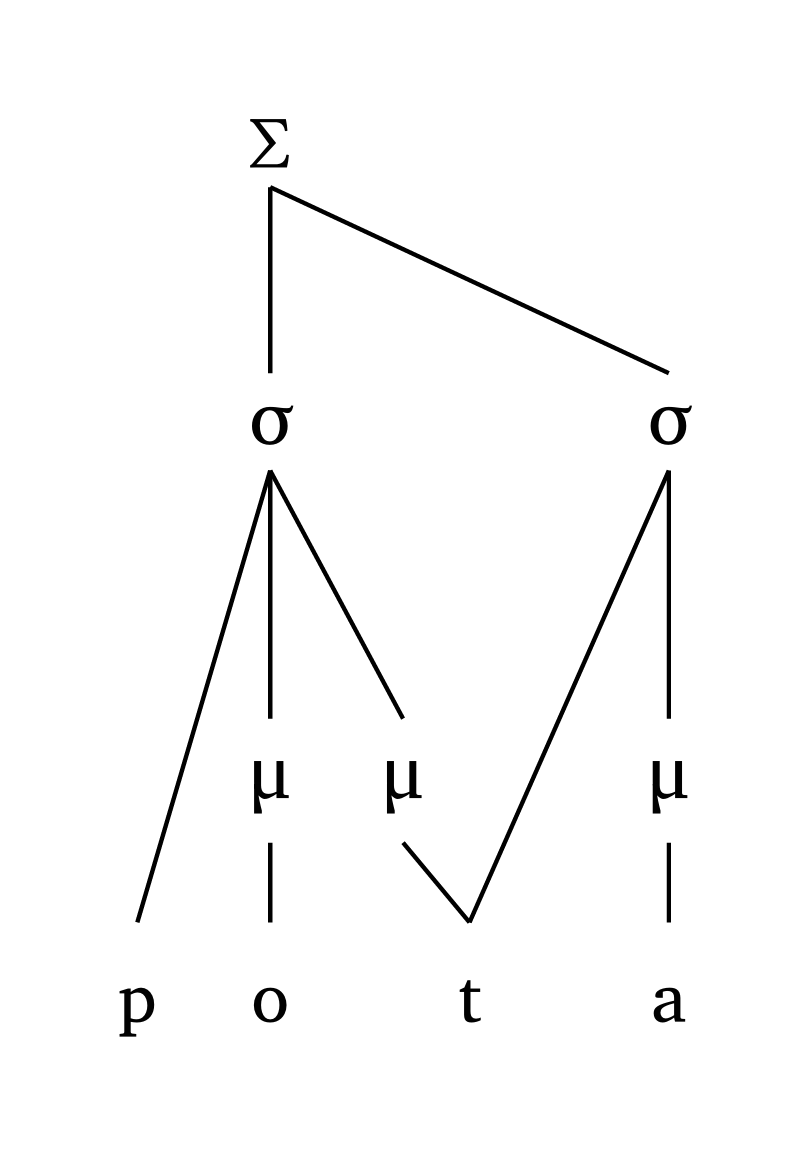
La hauteur de \(\Sigma\) est proportionnelle à la largeur de la représentation pour éviter la superposition de lignes dans les cas extrêmes, comme le montre Figure 25.
Pied extrême
#foot("'xa.xa.xa.xa.xa.xa.xa.xa.xa.xa.xa.xa", scale: 0.7)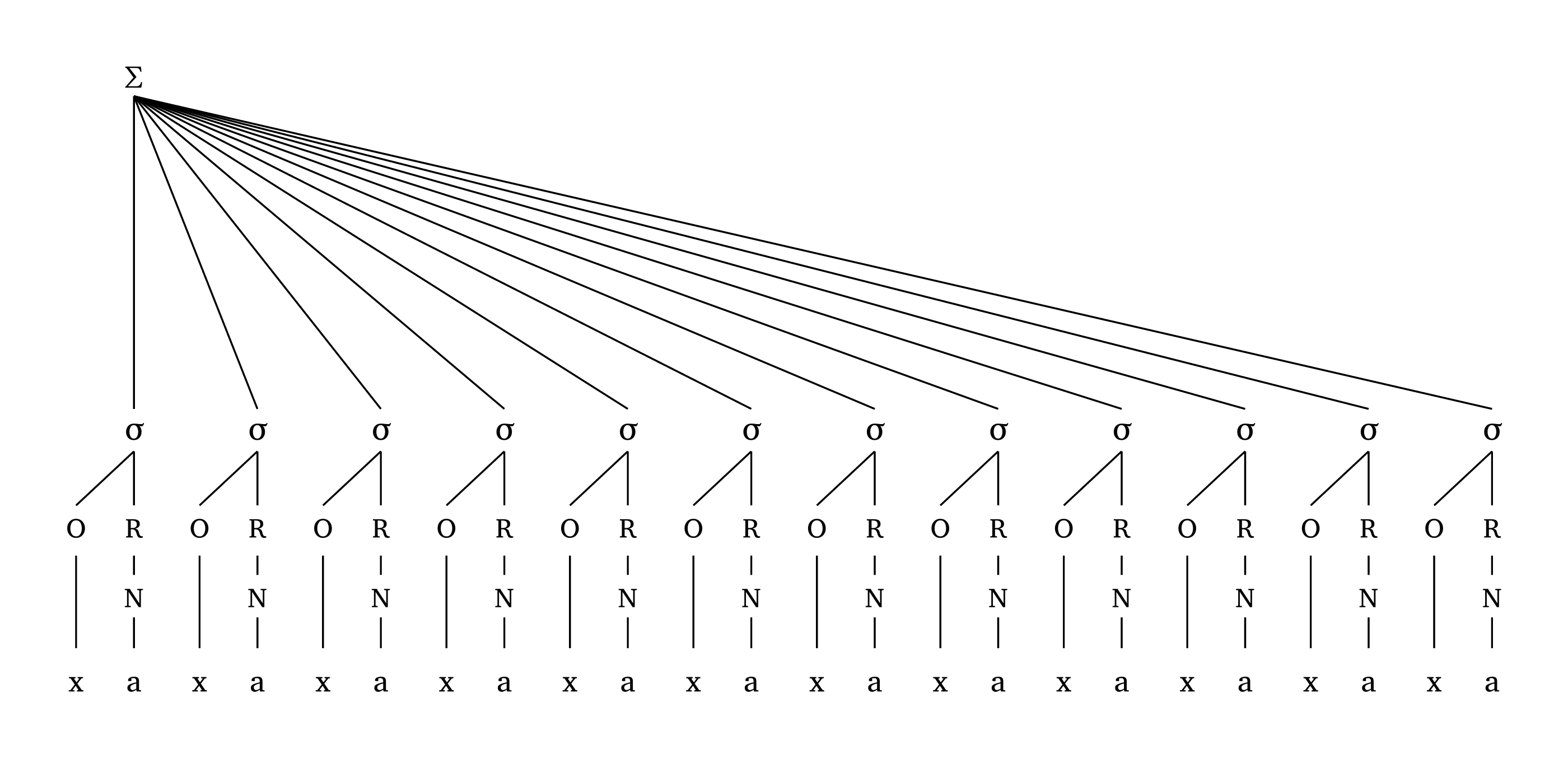
4.4 Mots prosodiques
Les parenthèses () définissent les pieds ; toute syllabe hors d’un pied est directement liée au mot prosodique. Une apostrophe ' marque la tête de chaque pied, et l’argument foot: "R" ou foot: "L" détermine quel pied porte l’accent primaire dans le mot (lorsque plus d’un pied est présent).
Mot prosodique (attaque-rime)
#word("('po.Ra).ma")Mot prosodique (moraïque)
#word-mora("('po.Ra).ma", coda: true)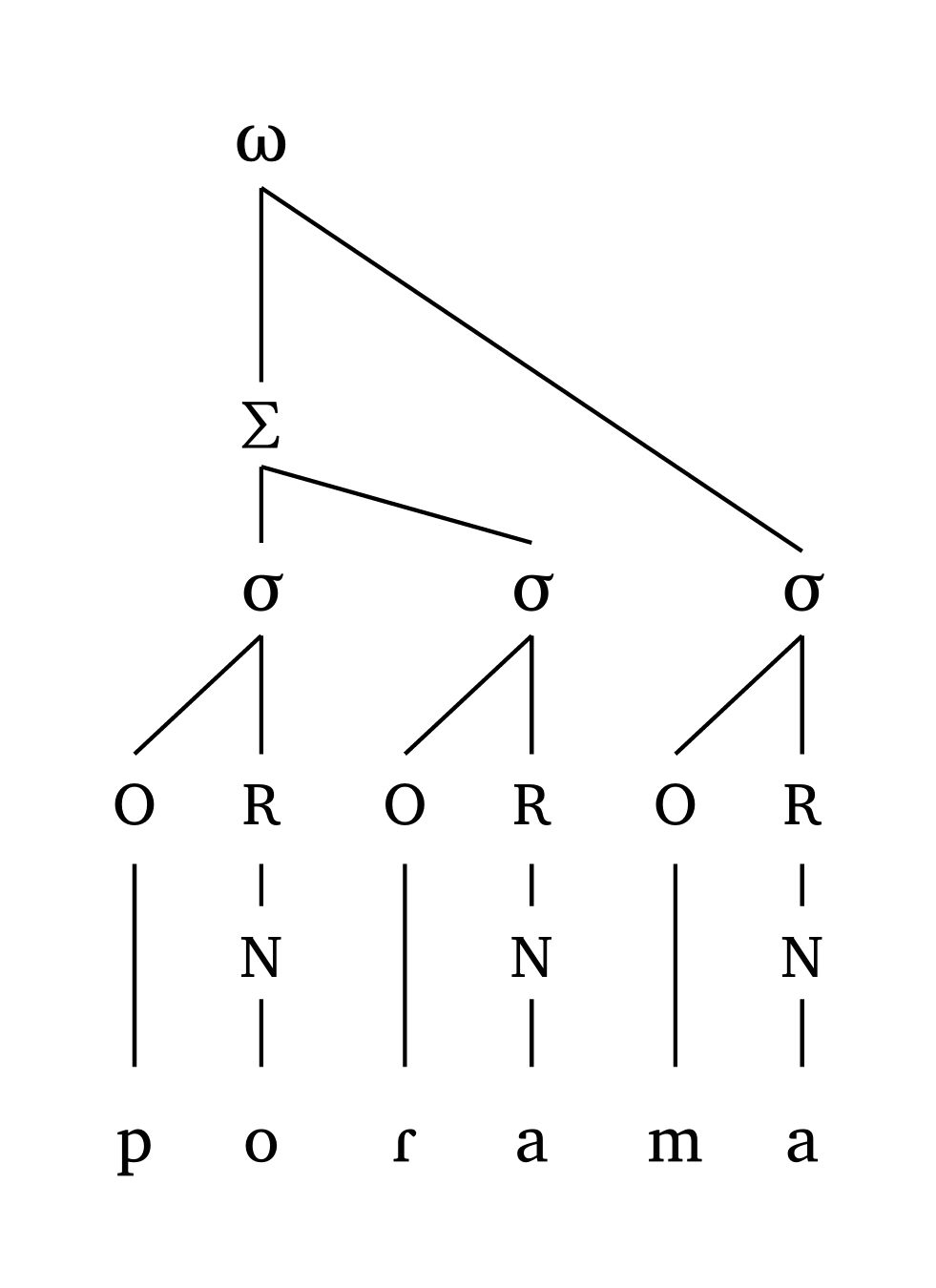
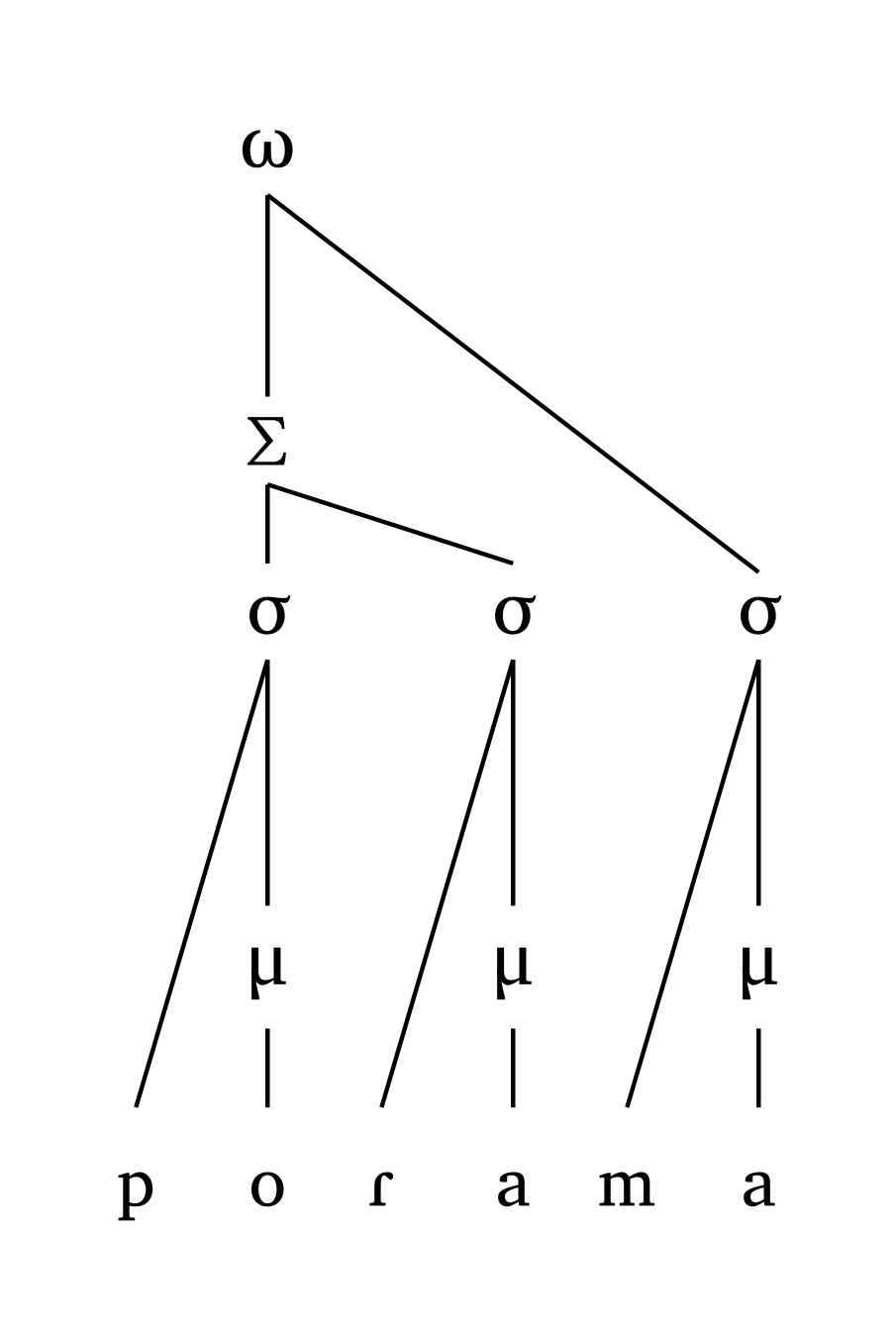
Mot prosodique à deux pieds, tête gauche
#word-mora("('po.Ra).('ma.pa)", foot: "L")Mot prosodique à deux pieds, tête droite
#word("('po.Ra).('ma.pa)", foot: "R")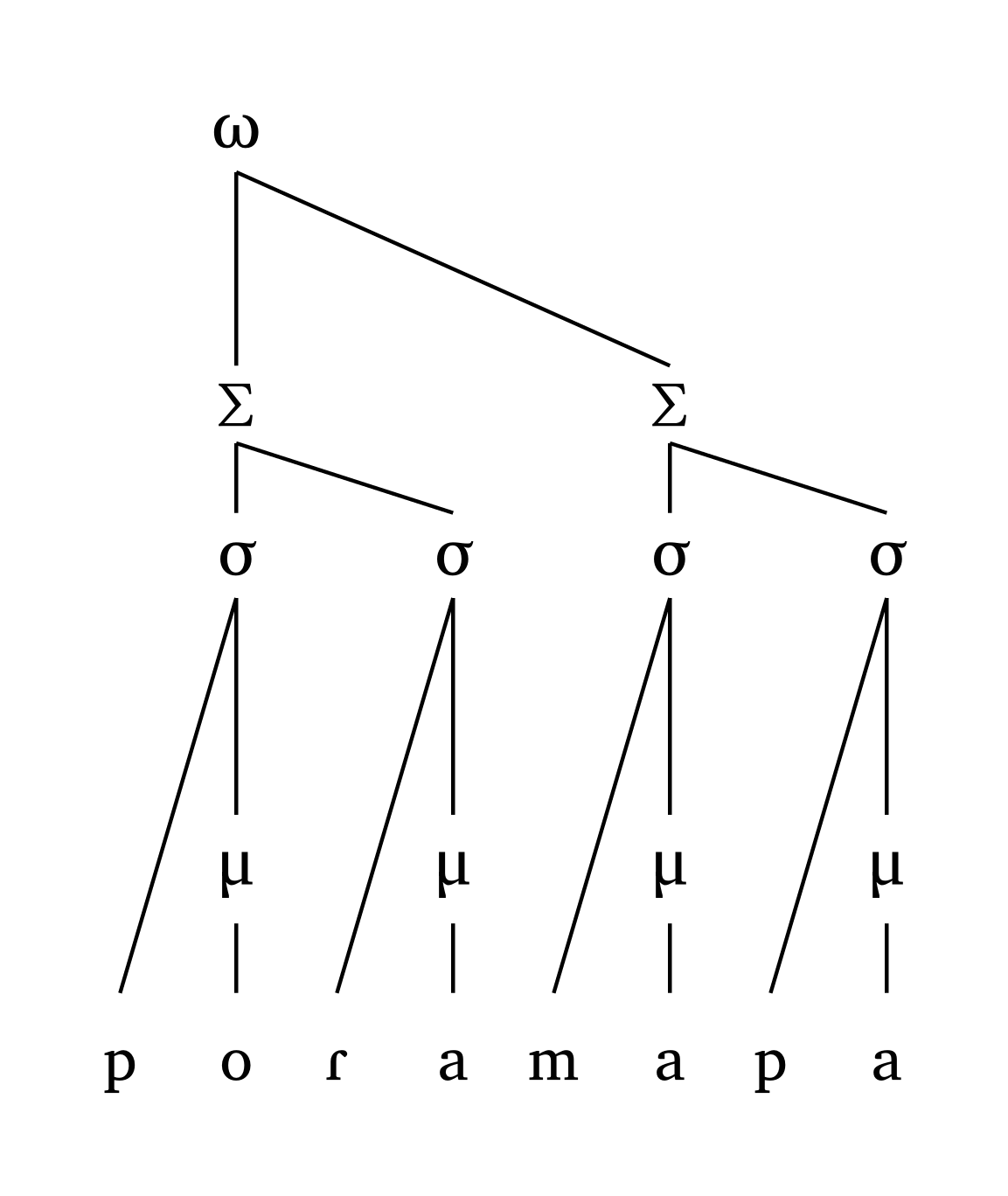
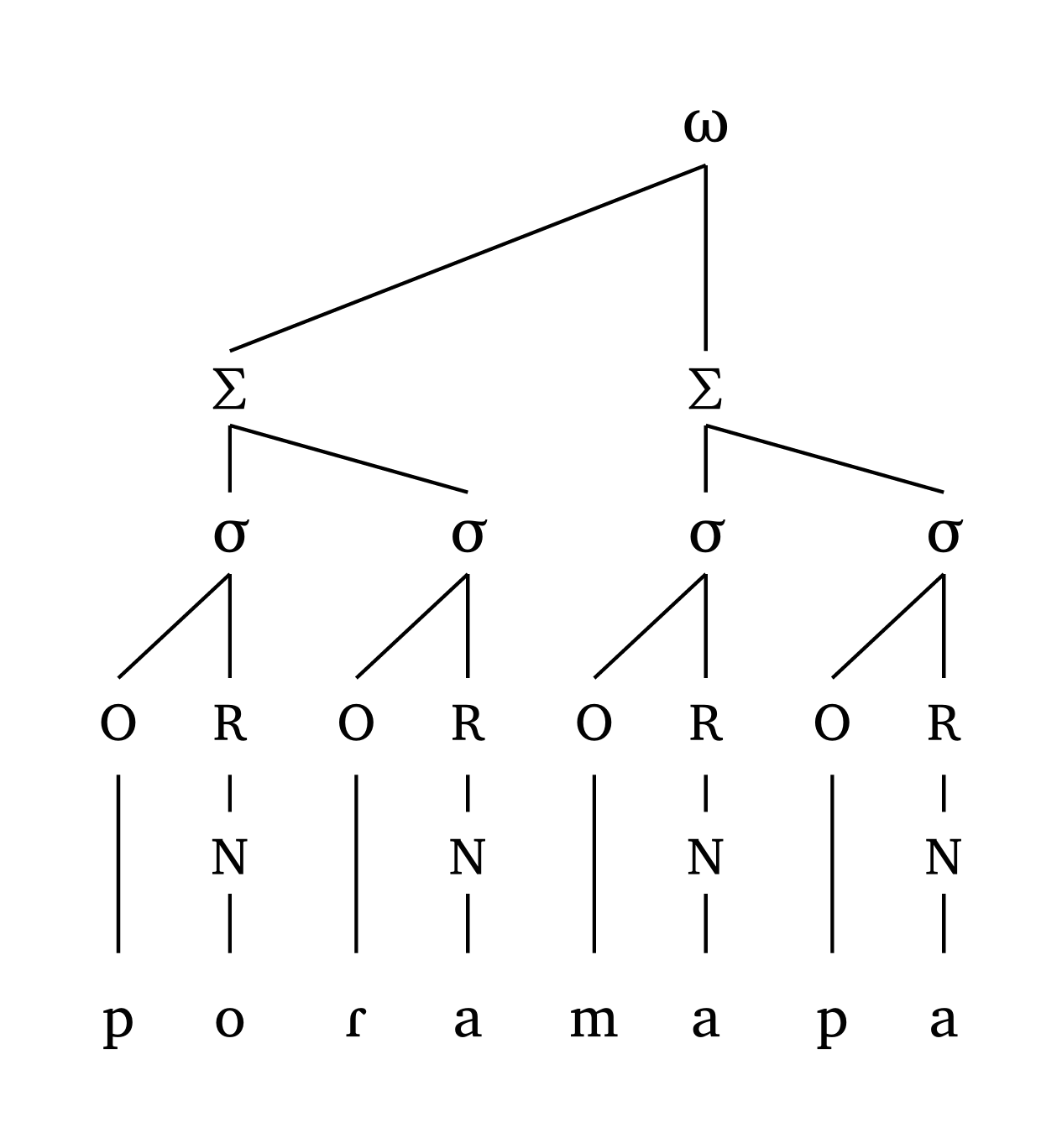
Toutes les lignes sont droites par conception (pas de lignes courbes). Dans les cas extrêmes — p. ex., lorsqu’une syllabe non-intégrée à un pied est très éloignée du pied principal — la hauteur est ajustée pour éviter les croisements de lignes, comme le montre Figure 30.
Mot prosodique extrême
#word("xa.(xa.xa)(xa.xa)(xa.xa)(xa.xa)", scale: 0.7)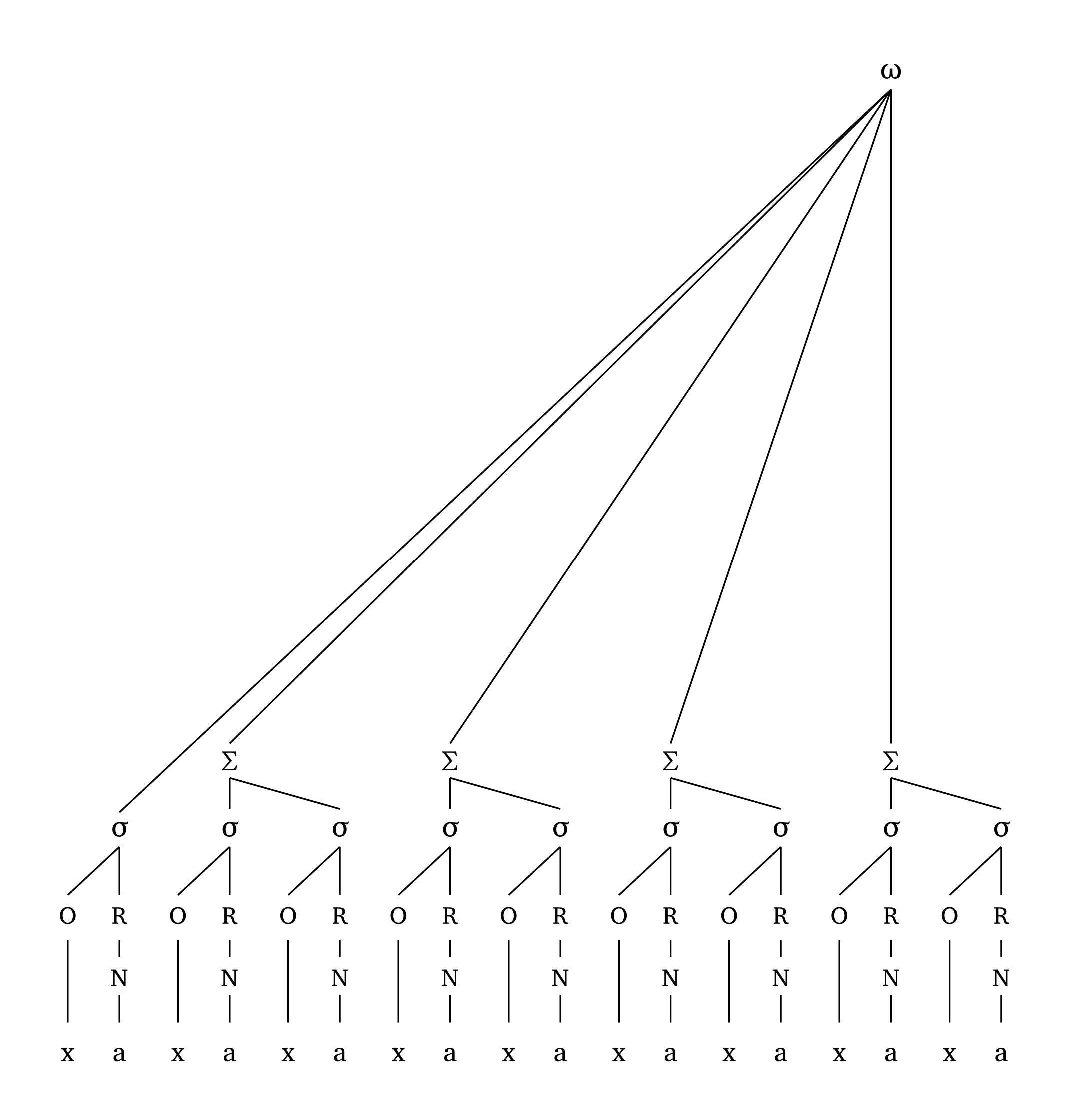
4.5 Grille métrique
La fonction #met-grid() crée une grille métrique en utilisant \(\times\) pour indiquer la proéminence. L’objectif est un rendu de haute qualité avec un effort minimal. Figure 31 et Figure 32 montrent des grilles pour le mot butterfly.
Grille métrique (entrée chaîne)
#met-grid("bu3.tter1.fly2")Grille métrique (entrée tuple/API)
#met-grid(("b2", 3), ("R \\schwar", 1), ("flaI", 2))
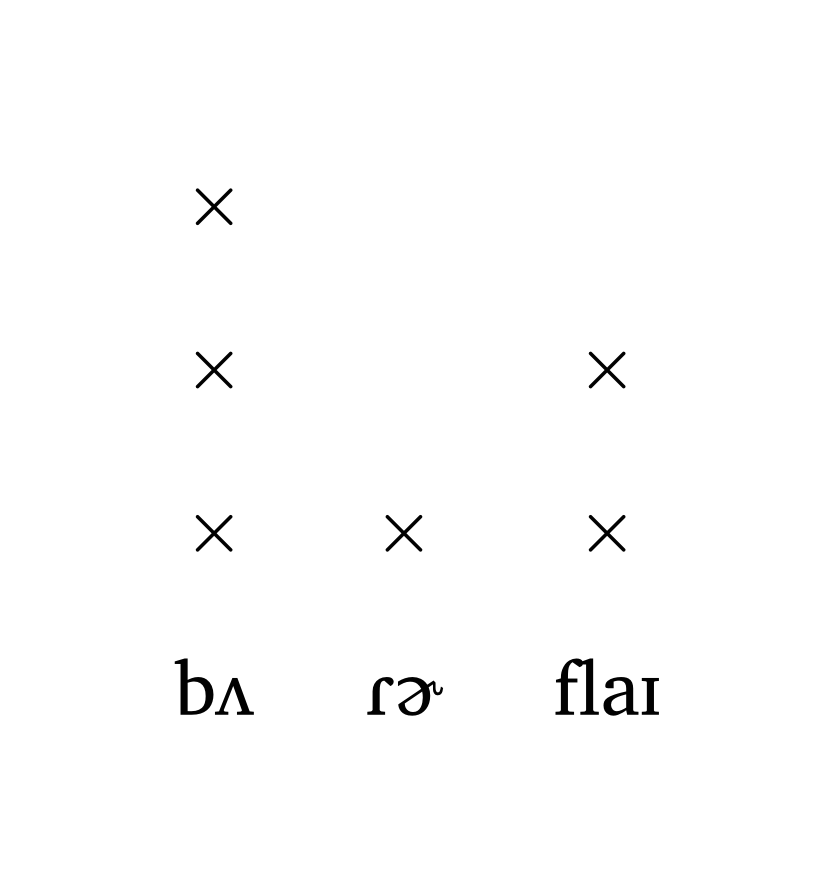
5 Autosegments
La fonction #autoseg() permet de représenter des traits ou des tons sur un niveau distinct, incluant la liaison, la déliaison, les tons flottants et les tons de contour. Les entrées sont des tableaux, donc chaque phonème est saisi individuellement. Cela permet des espaces vides, des symboles de frontière de domaine, etc.
5.1 Propagation de traits
Figure 33 illustre #autoseg() dans un scénario simple de propagation de traits. L’argument links est un tableau de tuples : ((2,1),) signifie « tracer un lien de l’indice 2 à l’indice 1 ». L’argument arrow ajoute ou supprime les têtes de flèches sur les lignes de liaison.
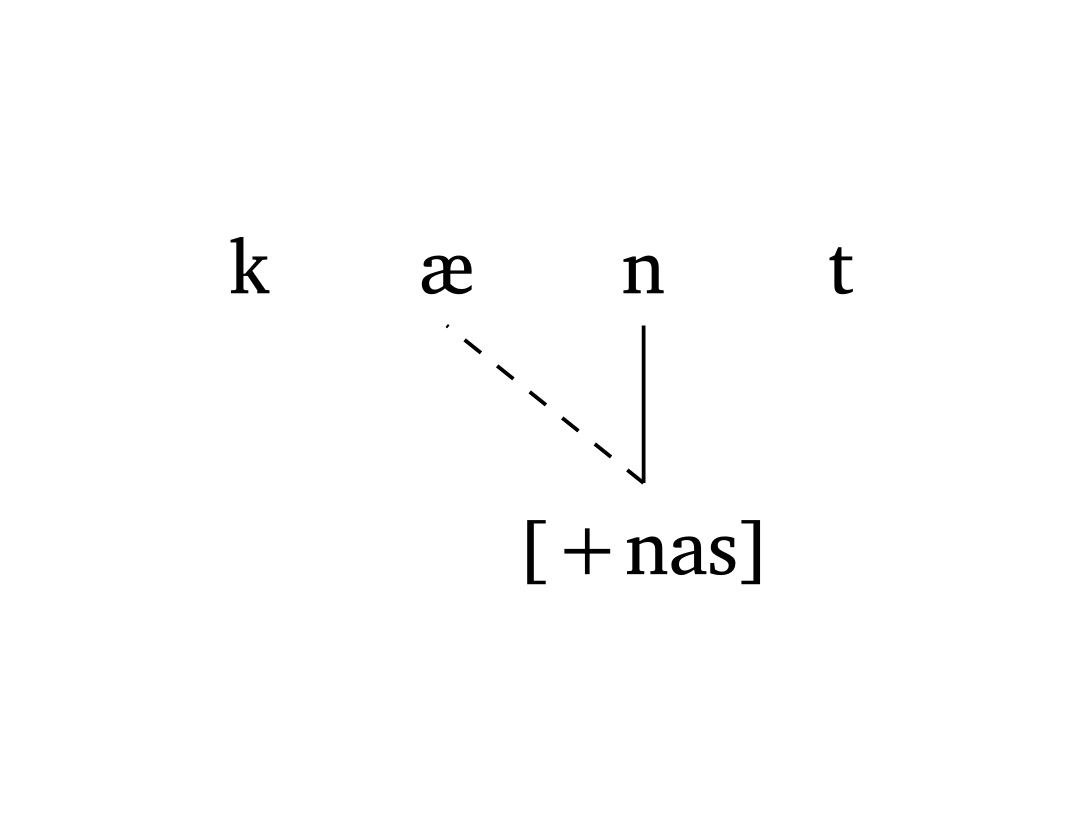
Propagation nasale
#autoseg(
("k", "\\ae", "n", "t"),
features: ("", "", "[+nas]", ""),
links: ((2, 1),),
spacing: 1.0,
arrow: false,
)Figure 34 montre un exemple de métaphonie dans le Vénète brésilien (Garcia et Guzzo 2023) où [+high] se propage du /i/ final vers /e/ (position 3) et /o/ (position 1). L’argument gloss permet une annotation rapide.
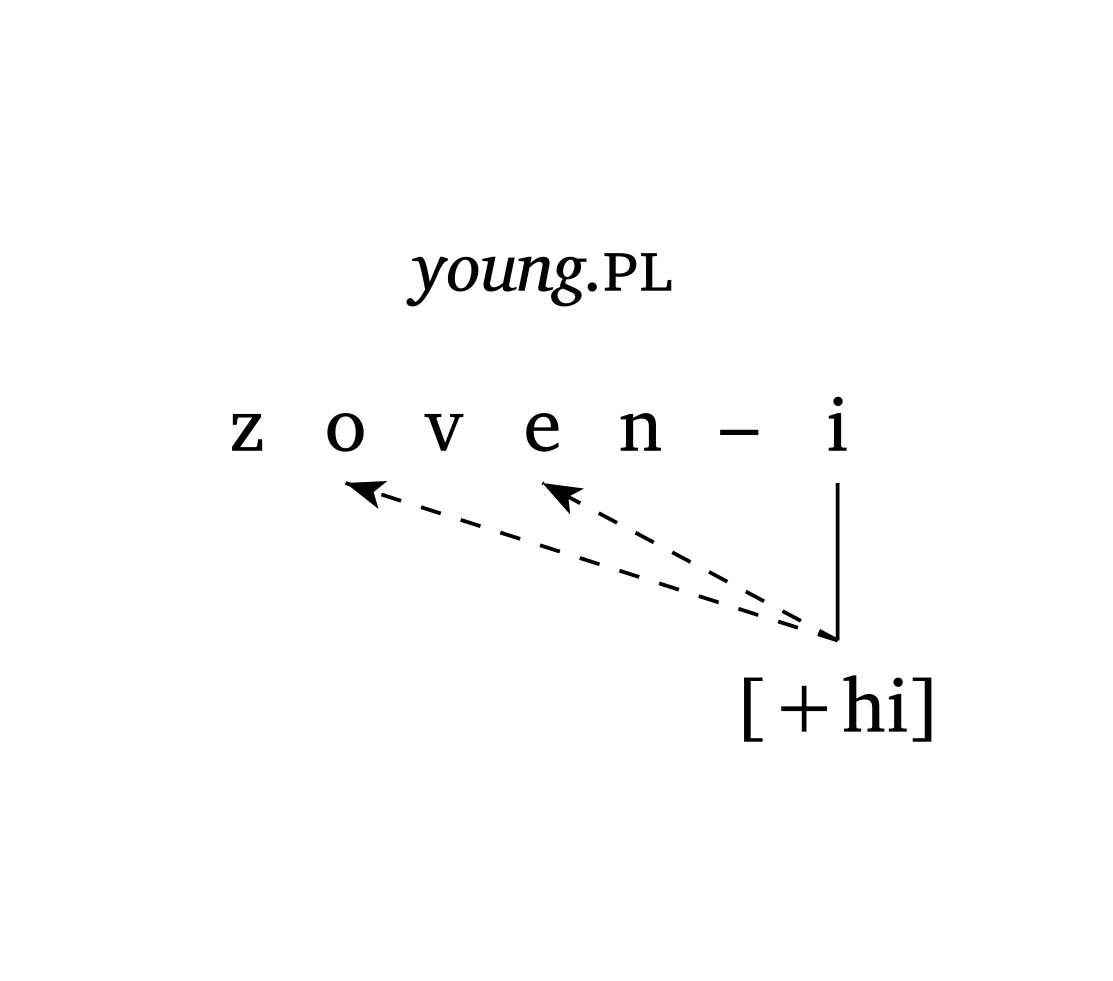
Métaphonie (Vénète brésilien)
#autoseg(
("z", "o", "v", "e", "n", "–", "i"),
features: ("", "", "", "", "", "", "[+hi]"),
links: ((6, 3), (6, 1)),
spacing: 0.5,
arrow: true,
gloss: [_young_#smallcaps(".pl")],
)5.2 Tons
L’argument tone: true « retourne » la représentation verticalement pour afficher les tons au-dessus du niveau segmental. Figure 35 montre la propagation du ton bas sans déliaison en Nupe (Zsiga 2013).
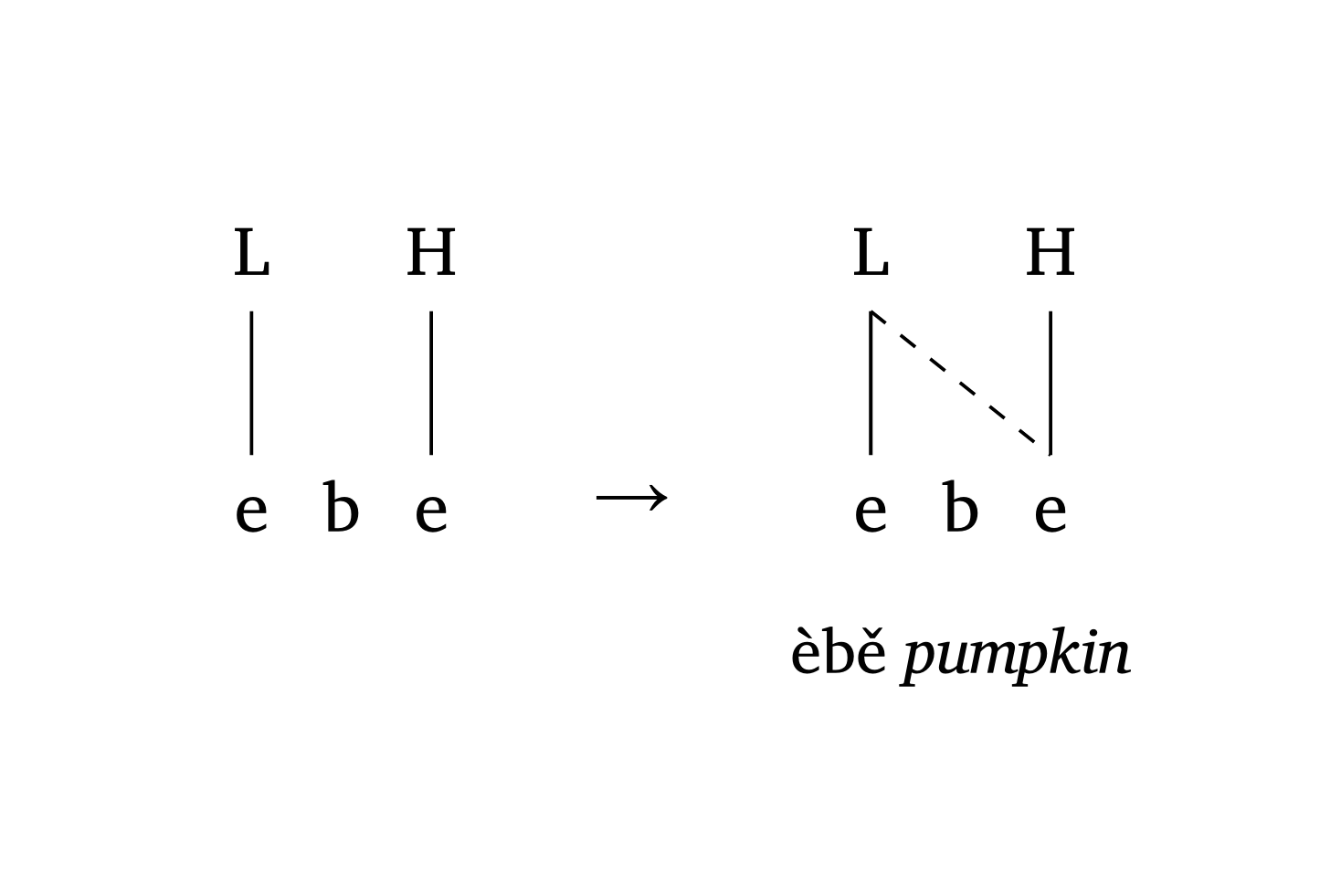
Propagation tonale (Nupe)
#autoseg(
("e", "b", "e"),
features: ("L", "", "H"),
spacing: 0.5,
tone: true,
gloss: [],
)
#a-r // arrow between stages
#autoseg(
("e", "b", "e"),
features: ("L", "", "H"),
links: ((0, 2),),
spacing: 0.5,
tone: true,
gloss: [èbě _pumpkin_],
)Les tons flottants peuvent être ajoutés avec l’argument float. Figure 36 montre comment ajouter un ton flottant et dessiner un cercle autour de lui avec l’argument highlight.
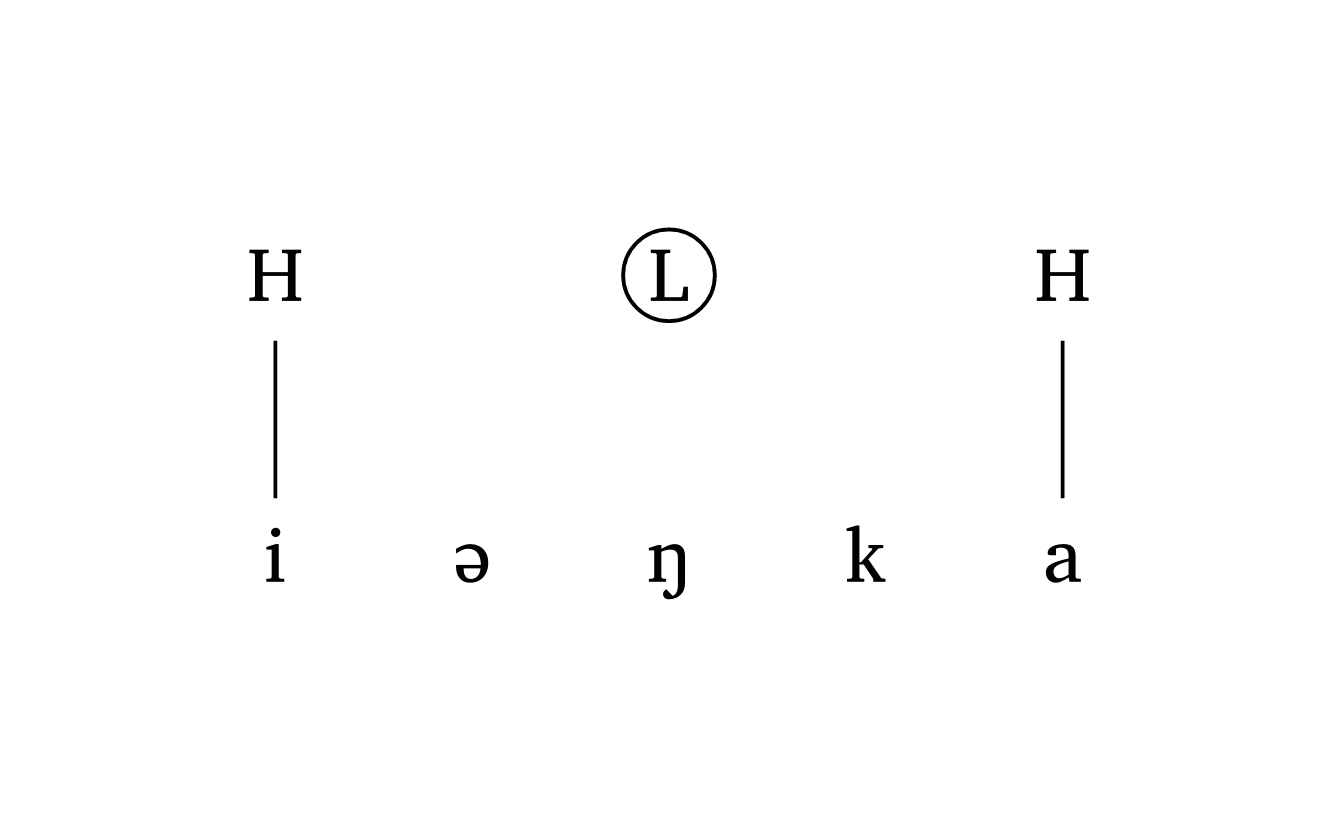
Ton flottant
#autoseg(
("i", "@", "N", "k", "a"),
features: ("H", "", "L", "", "H"),
highlight: (2,),
spacing: 1.0,
tone: true,
float: (2,),
)La propagation à partir d’un ton de contour requiert un tuple dans features pour la voyelle liée à deux tons. L’argument links utilise des tuples imbriqués : (((2, 0), 1),) signifie « du premier ton à la position 2 (c.-à-d. H), tracer une ligne en pointillés vers le segment 1 ». Figure 37 illustre cela.
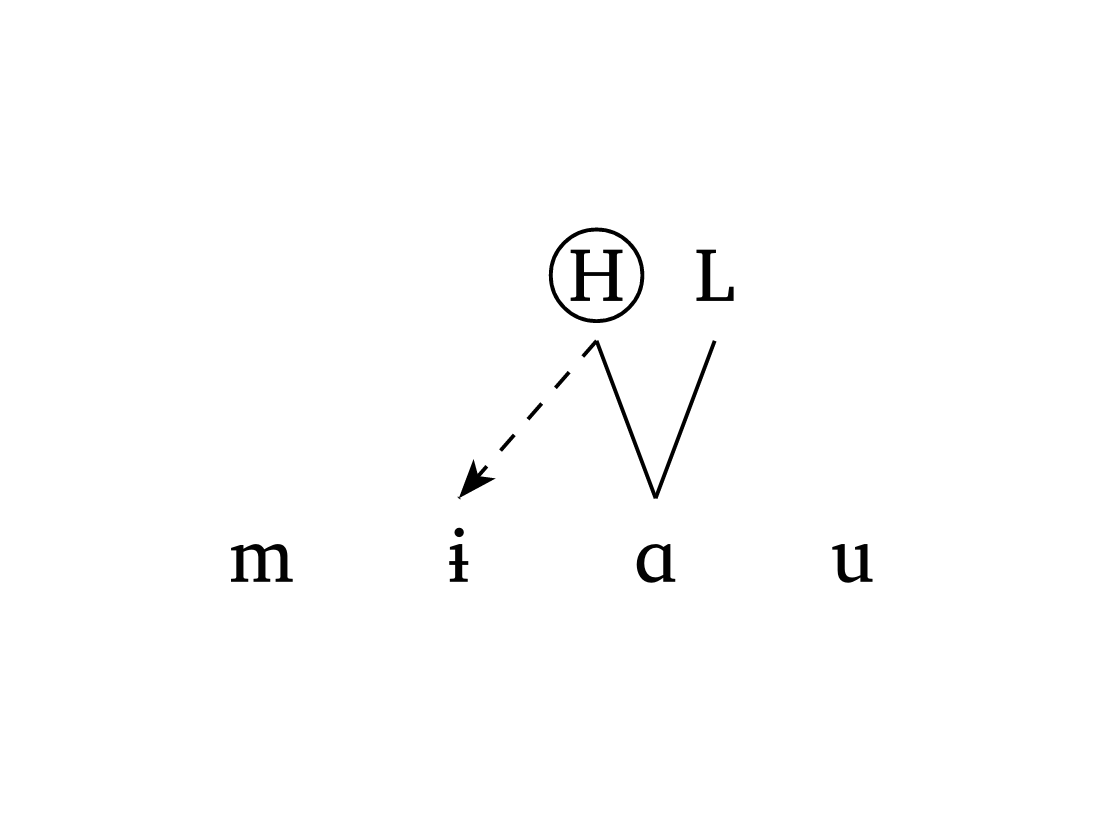
Ton de contour
#autoseg(
("m", "1", "A", "u"),
features: ("", "", ("H", "L"), ""),
links: (((2, 0), 1),),
tone: true,
highlight: ((2, 0),),
spacing: 1.0,
arrow: true,
),Figure 38 montre un effet OCP en trois étapes dans le Vaï (Zsiga 2013), illustrant la déliaison (delinks) et les relations tonales un-à-plusieurs (multilinks). L’argument delinks: ((3, 3),) indique que le lien entre la position 3 et elle-même doit être délié. L’argument multilinks: ((6, (6, 9)),) signifie « centrer un ton sur les segments 6 et 9 simultanément ».
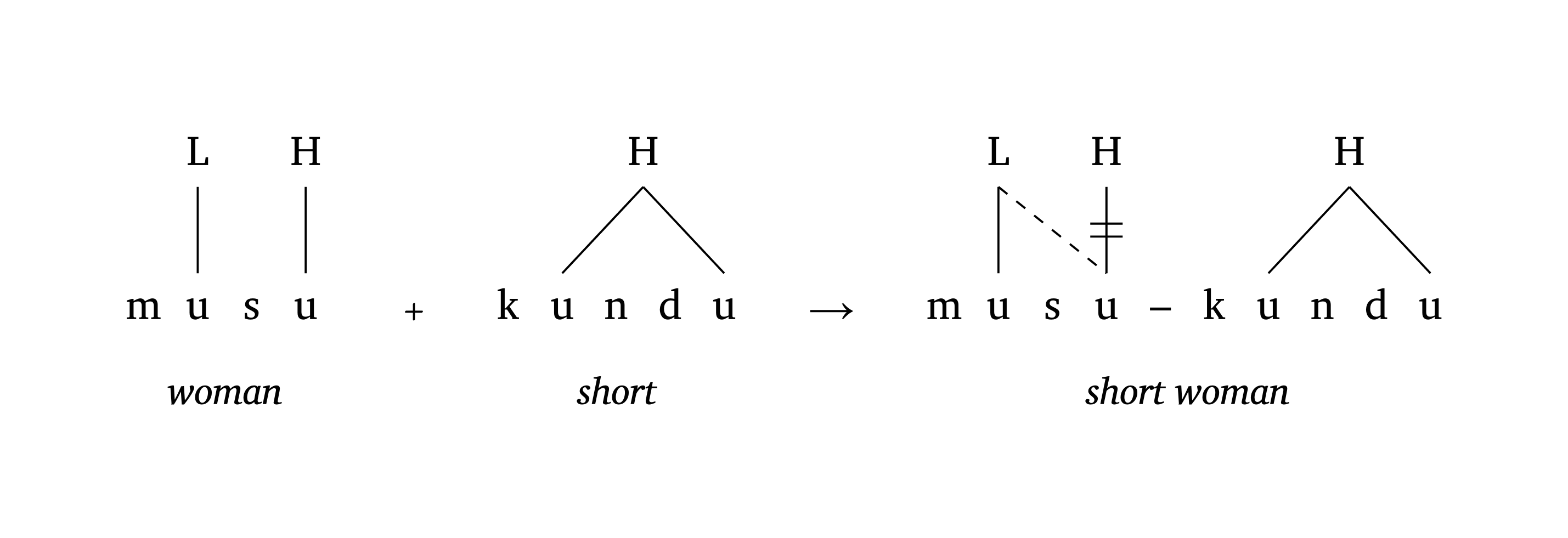
Effets OCP (Vaï)
#autoseg(
("m", "u", "s", "u"),
features: ("", "L", "", "H"),
tone: true, spacing: 0.5, baseline: 37%,
gloss: [_woman_],
) +
#autoseg(
("k", "u", "n", "d", "u"),
features: ("", "H", "", "", ""),
tone: true,
float: (1,),
multilinks: ((1, (1, 4)),),
spacing: 0.5, baseline: 37%,
arrow: false,
gloss: [_short_],
) #a-r
#autoseg(
("m", "u", "s", "u", "–", "k", "u", "n", "d", "u"),
features: ("", "L", "", "H", "", "", "H", "", "", ""),
links: ((1, 3),),
delinks: ((3, 3),),
arrow: false,
multilinks: ((6, (6, 9)),),
tone: true,
baseline: 37%,
spacing: 0.50,
gloss: [_short woman_],
)5.3 Prosodie avec ToBI
L’ajout d’étiquettes ToBI aux chaînes peut être réalisé avec la fonction #int(). L’argument line: false désactive la tige verticale (p. ex., pour les tons de frontière). Par défaut, la taille de police des tons est 0.8em.
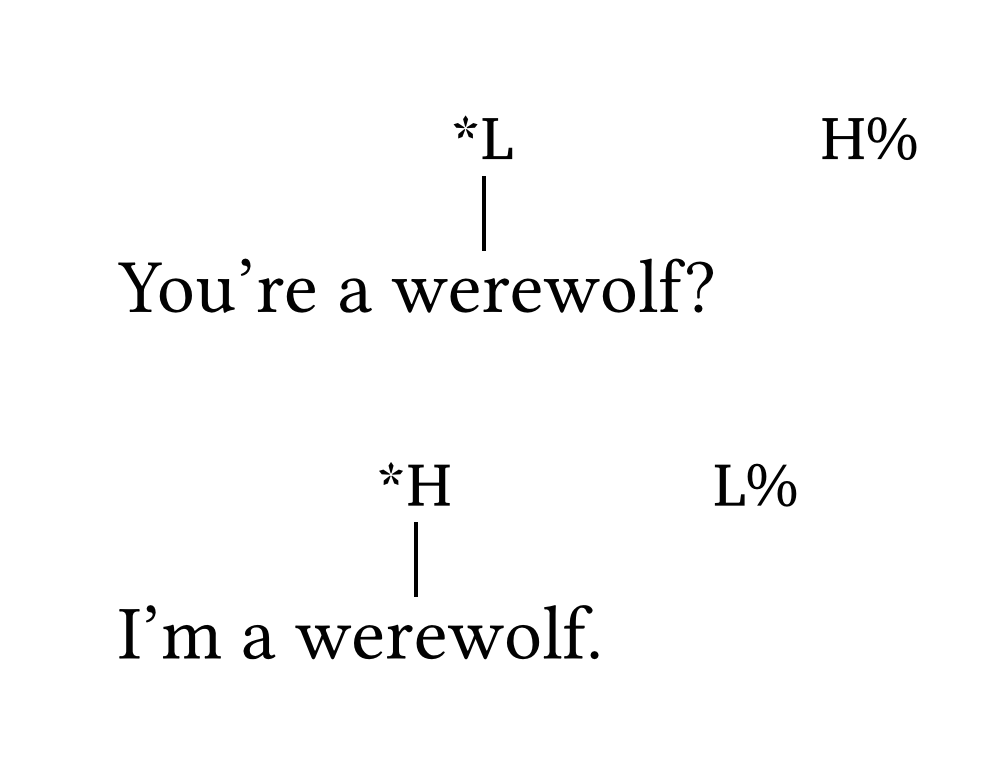
ToBI en ligne
You're a we#int("*L")rewolf?#h(2em)#int("H%", line: false)
I'm a wer#int("*H")ewolf.#h(2em)#int("L%", line: false)Notez que #int() n’est pas destiné à être utilisé dans les listes numérotées/non numérotées. Dans la grande majorité des cas, les chaînes avec des étiquettes ToBI apparaîtront dans des exemples numérotés — voir la section Exemples numérotés.
5.4 Multi-niveaux
La fonction #multi-tier() offre la liberté de créer une large gamme de structures non linéaires qui ne peuvent pas être générées par des fonctions à usage unique. L’argument principal est levels, un tableau de rangées, où chaque rangée est un tableau d’éléments. Les éléments sont automatiquement liés à l’élément du niveau inférieur ; des liens supplémentaires peuvent être spécifiés avec l’argument links.
Figure 40 reproduit une figure de Booij (2012, 159) sur l’interface de la phonologie et de la morphologie. Figure 41 montre la même figure avec show-grid: true pour aider à visualiser les positions.
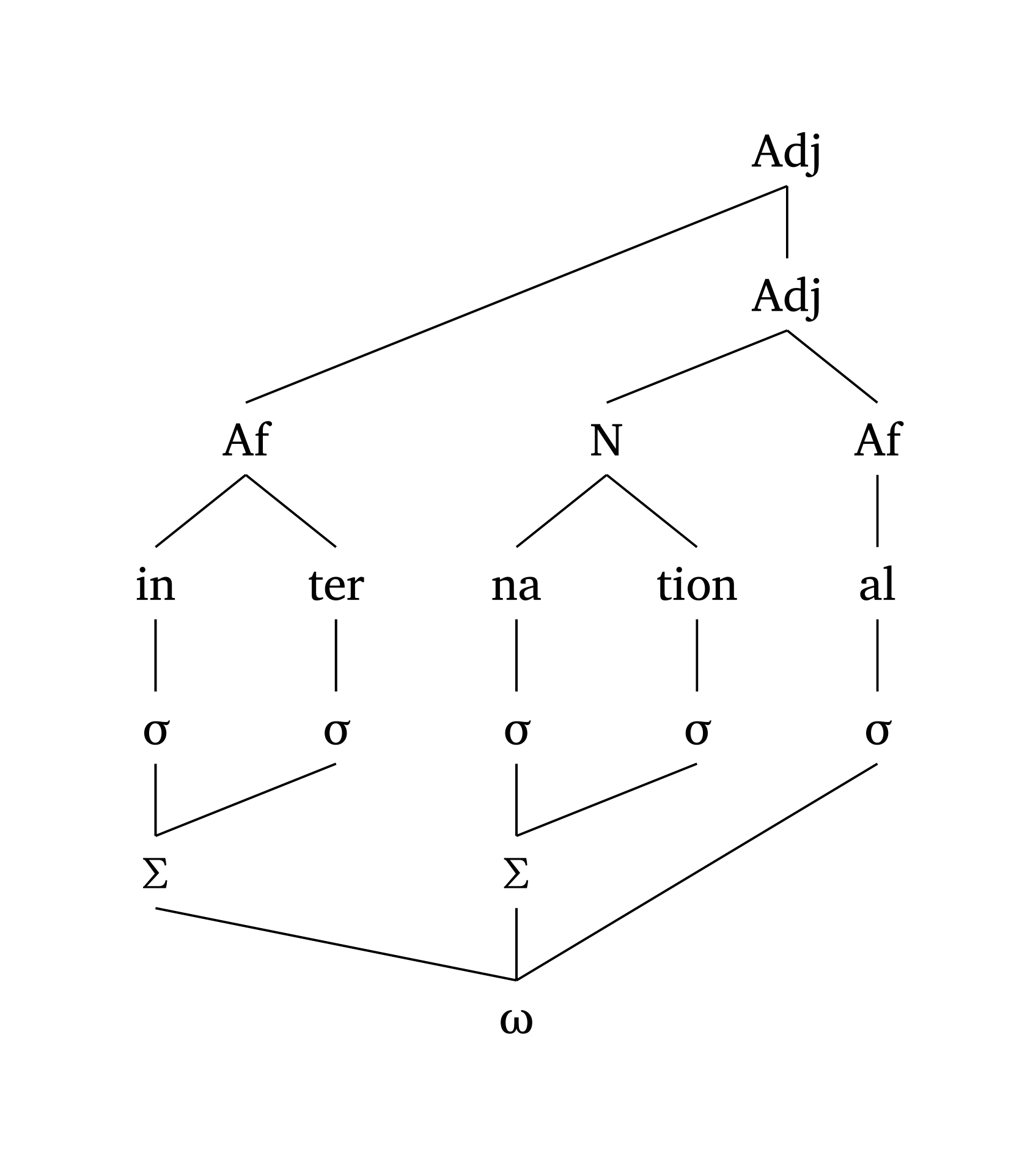
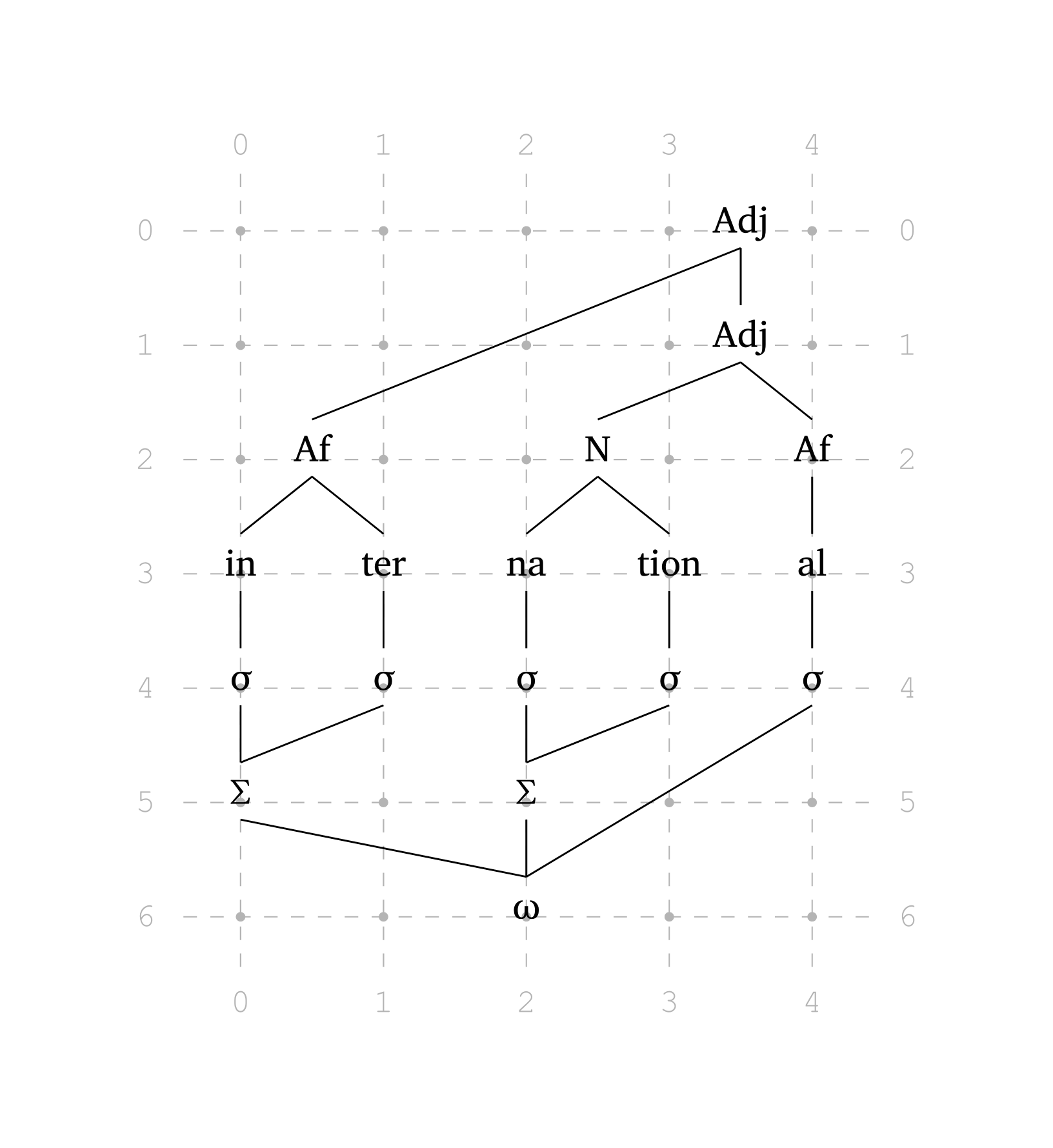
Multi-niveaux (morphophonologie)
#multi-tier(
show-grid: true, // <- to help you see the grid
levels: (
("", "", "", "", ("Adj", 3.5)),
("", "", "", "", ("Adj", 3.5)),
("", ("Af", 0.5), "", ("N", 2.5), "Af"),
("in", "ter", "na", "tion", "al"),
("sigma", "sigma", "sigma", "sigma", "sigma"),
("Sigma", "", "Sigma", "", ""),
("", "", "omega", "", ""),
),
links: (
((0, 4), (2, 1)), // Adj -> Af
((1, 4), (2, 3)), // Adj -> N
((2, 1), (3, 0)), // Af -> in
((2, 3), (3, 2)), // N -> na
((5, 0), (4, 1)), // Ft -> Syl
((5, 2), (4, 3)), // Ft -> Syl
((6, 2), (5, 0)), // PWd -> Ft
((6, 2), (4, 4)), // PWd -> Ft
),
)Les éléments spécifiés comme ("N", 2.5) sont placés à des positions fractionnaires sur la grille. La fonction détecte également automatiquement les lettres grecques : "sigma" est rendu comme \(\sigma\), "Sigma" comme \(\Sigma\), "omega" comme \(\omega\). Les chiffres dans les éléments sont automatiquement rendus en indice.
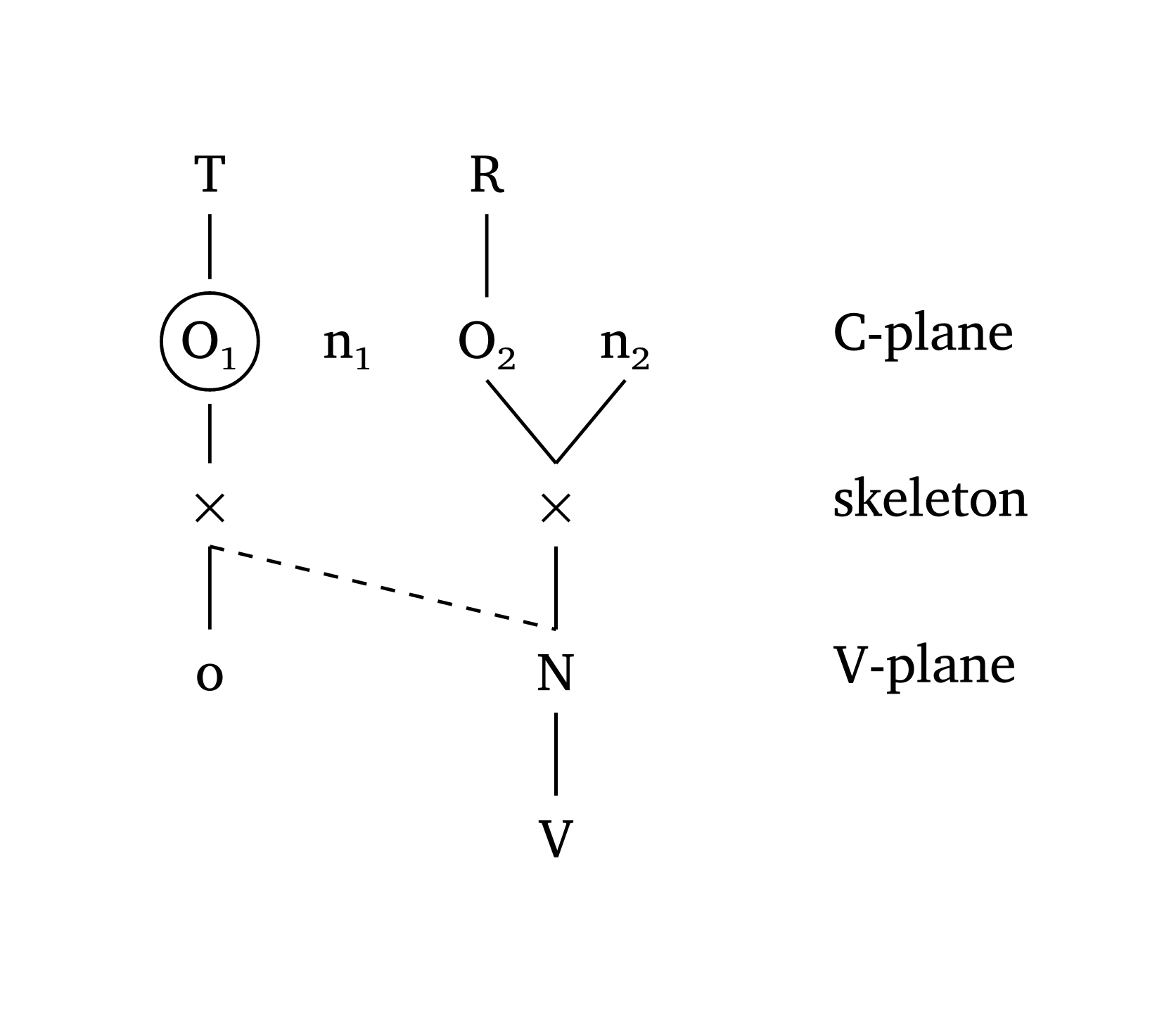
#multi-tier() peut également créer des représentations de Phonologie du gouvernement et de Phonologie CV. Figure 42, adapté de Goad (2012, 355), montre comment les flèches et arrow-delinks fonctionnent. Il est également possible d’étiqueter les niveaux, comme le montre Figure 43, adapté de Carvalho (2017).
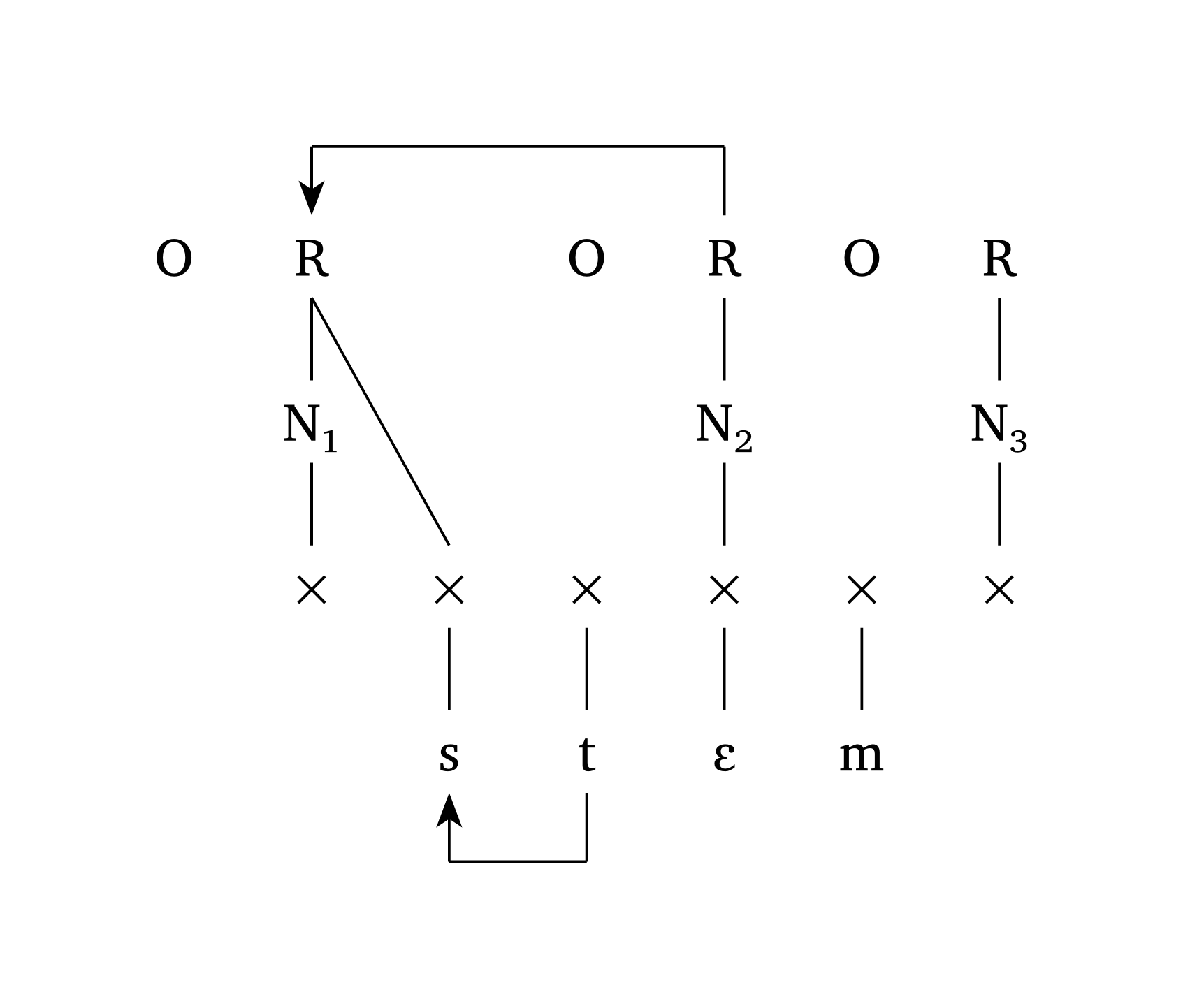
Phonologie du gouvernement
#multi-tier(
levels: (
("O", "R", "", "O", "R", "O", "R"),
("", "N1", "", "", "N2", "", "N3"),
("", "x", "x", "x", "x", "x", "x"),
("", "", "s", "t", "E", "m", ""),
),
links: (((0, 1), (2, 2)),),
ipa: (3,),
arrows: (
((3, 3), (3, 2)),
((0, 4), (0, 1)),
),
arrow-delinks: ((1,)),
spacing: 1,
)Phonologie CV avec étiquettes de niveaux
#multi-tier(
levels: (
("T", "", "R", ""),
("O1", "n1", "O2", "n2"),
("x", "", ("x", 2.5), ""),
("o", "", ("N", 2.5), ""),
("", "", ("V", 2.5), ""),
),
links: (((1, 3), (2, 2)),),
dashed: (((2, 0), (3, 2)),),
level-spacing: 1.2,
highlight: ((1, 0),),
spacing: 1,
stroke-width: 0.7pt,
tier-labels: (
(1, "C-plane"),
(2, "skeleton"),
(3, "V-plane"),
),
scale: 1,
)6 Géométrie des traits
La géométrie des traits présente des défis importants, notamment l’interface utilisateur : si trop de degrés de liberté sont disponibles, une fonction devient trop complexe. phonokit offre deux fonctions dédiées : #geom() pour les arbres à segment unique et #geom-group() pour les arbres multiples et les processus.
6.1 Arbres simples
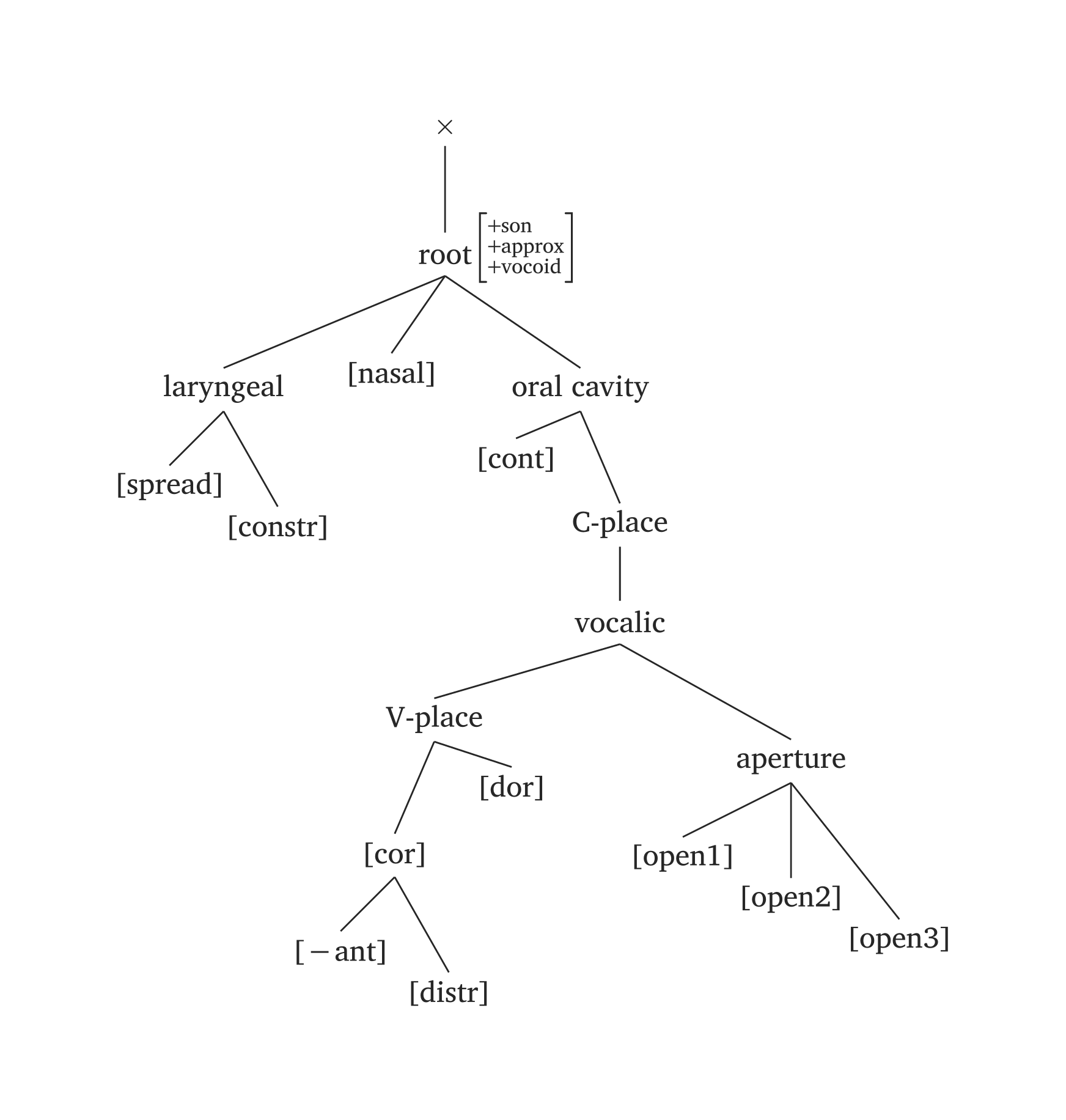
Les arguments de #geom() sont nommés d’après les nœuds qu’ils ajoutent. Si vous ajoutez un nœud \(n\), la fonction construit automatiquement les nœuds parents nécessaires. Par exemple, ajouter voice: true ajoute également [laryngeal] ; ajouter anterior: true ajoute également [coronal]. Les arguments acceptent les valeurs booléennes et les chaînes : nasal: true ajoute [nasal], tandis que nasal: "+" ajoute [+nasal].
Figure 44 reproduit la représentation consonantique complète de Clements et Hume (1995, 292).
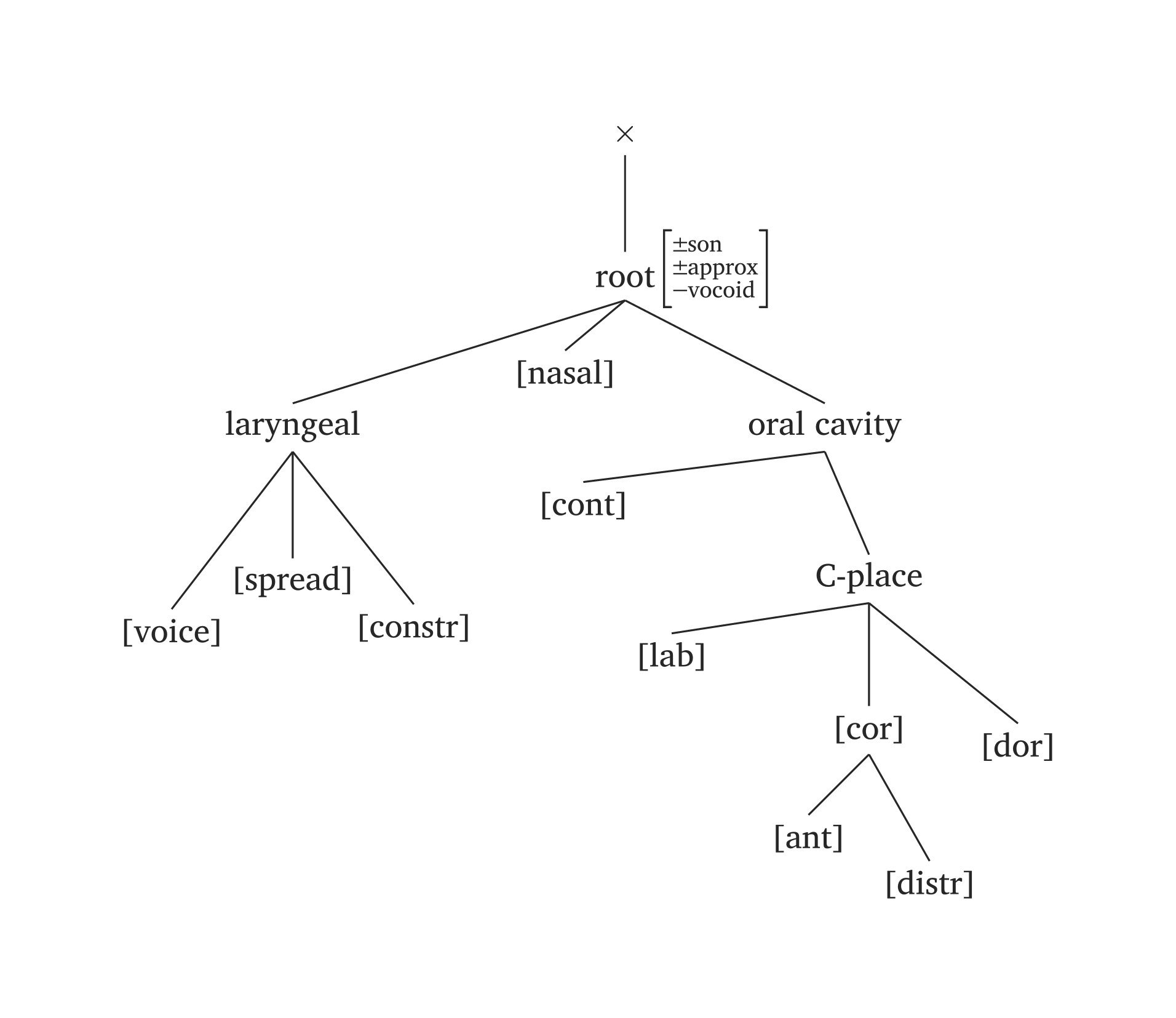
Géométrie des traits consonantiques complète
#geom(
root: ("±son", "±approx", "-vocoid"),
spread: true,
constricted: true,
nasal: true,
voice: true,
labial: true,
anterior: true,
distributed: true,
dorsal: true,
continuant: true,
)Géométrie des traits vocaliques complète
#geom(
root: ("+son", "+approx", "+vocoid"),
spread: true,
constricted: true,
nasal: true,
vplace: true,
aperture: (true, true, true),
coronal: true,
anterior: "-",
distributed: true,
dorsal: true,
continuant: true,
scale: 0.9,
)Plusieurs phonèmes sont prédéfinis dans #geom() via l’argument ph, en utilisant les mêmes conventions que #ipa(). Dans les figures ci-dessous, seul le code #geom(ph: "...") est nécessaire. Vous noterez également les unités temporelles ajoutées par défaut (x). Vous pouvez désactiver les unités temporelles en ajoutant timing: false, ou ajouter des mores à la place (timing: "mora" ou timing: "mu"). L’argument timing accepte également un tableau pour les voyelles longues : timing: ("x", "x"). Par exemple, si vous préférez les mores aux cases x, vous ajouteriez timing: ("mora", "mora") pour la voyelle longue dans Figure 47.
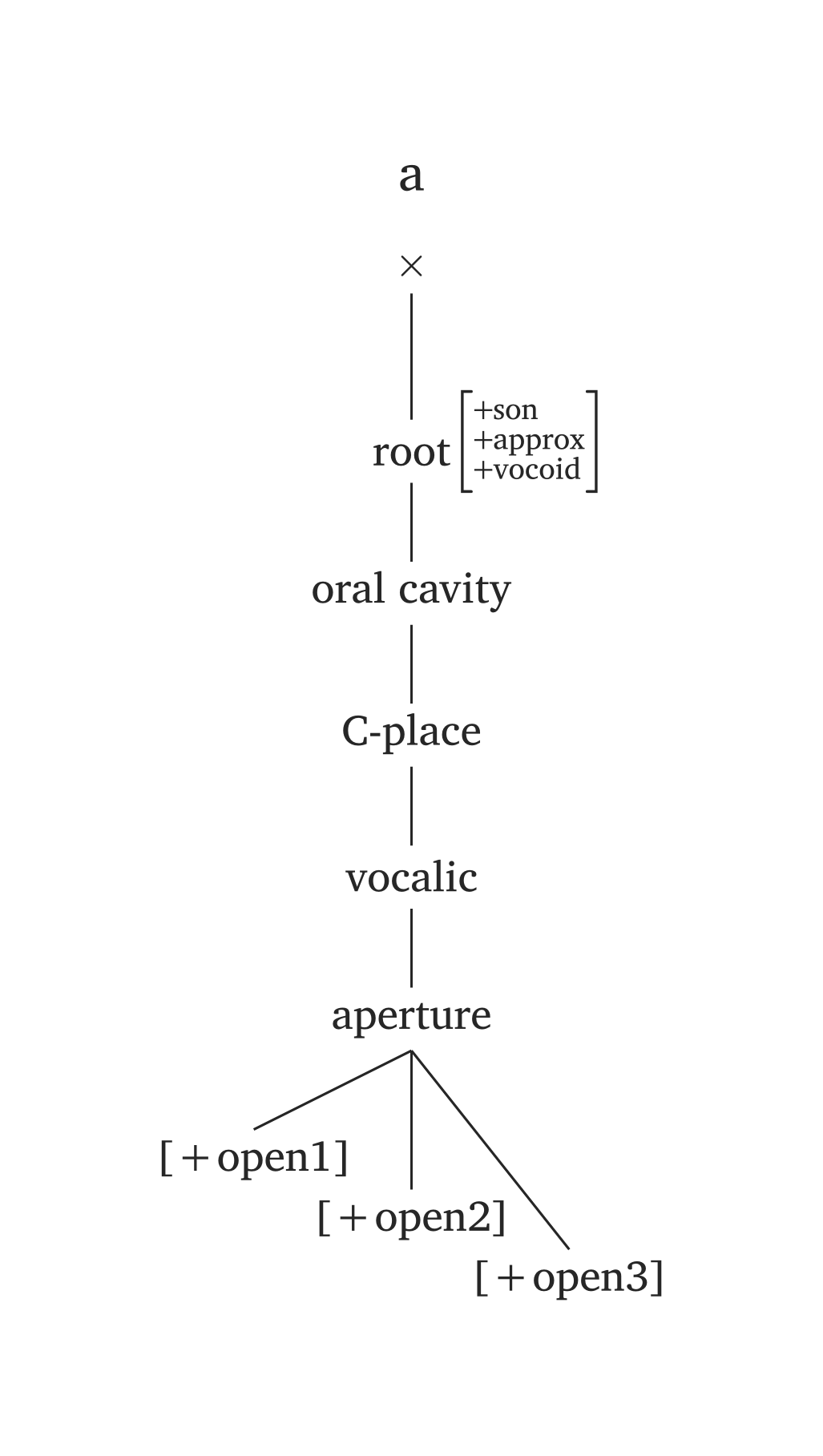
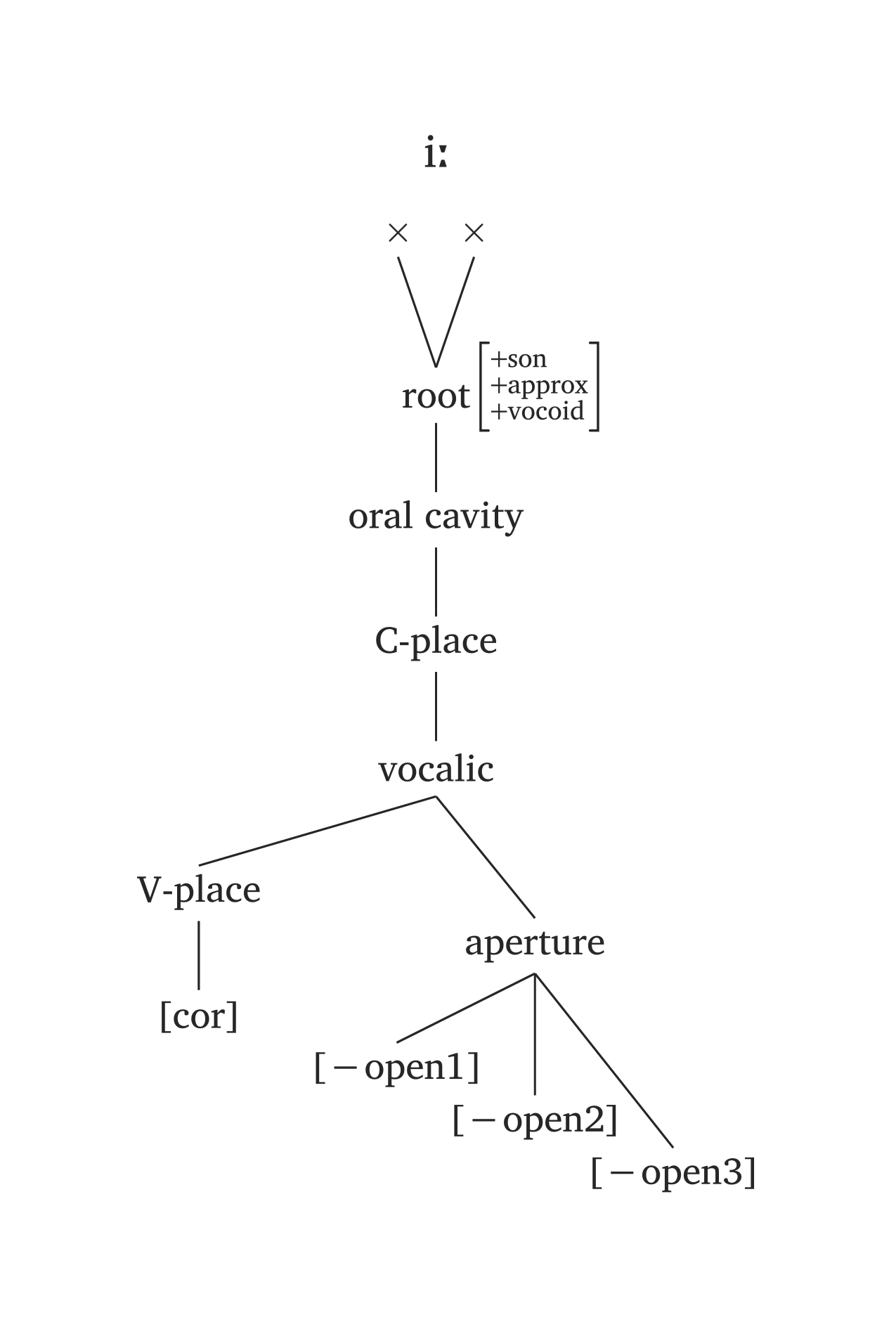
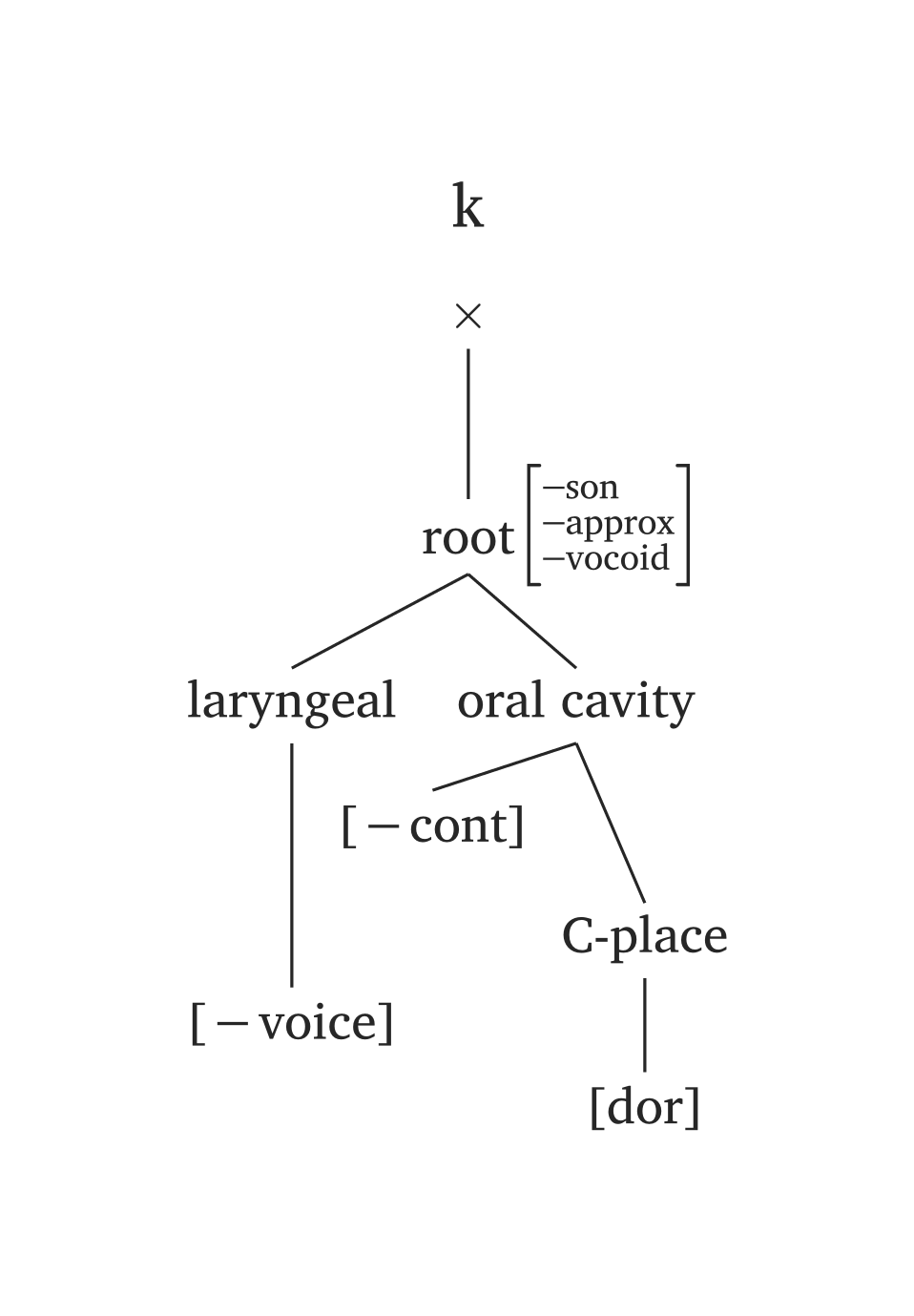
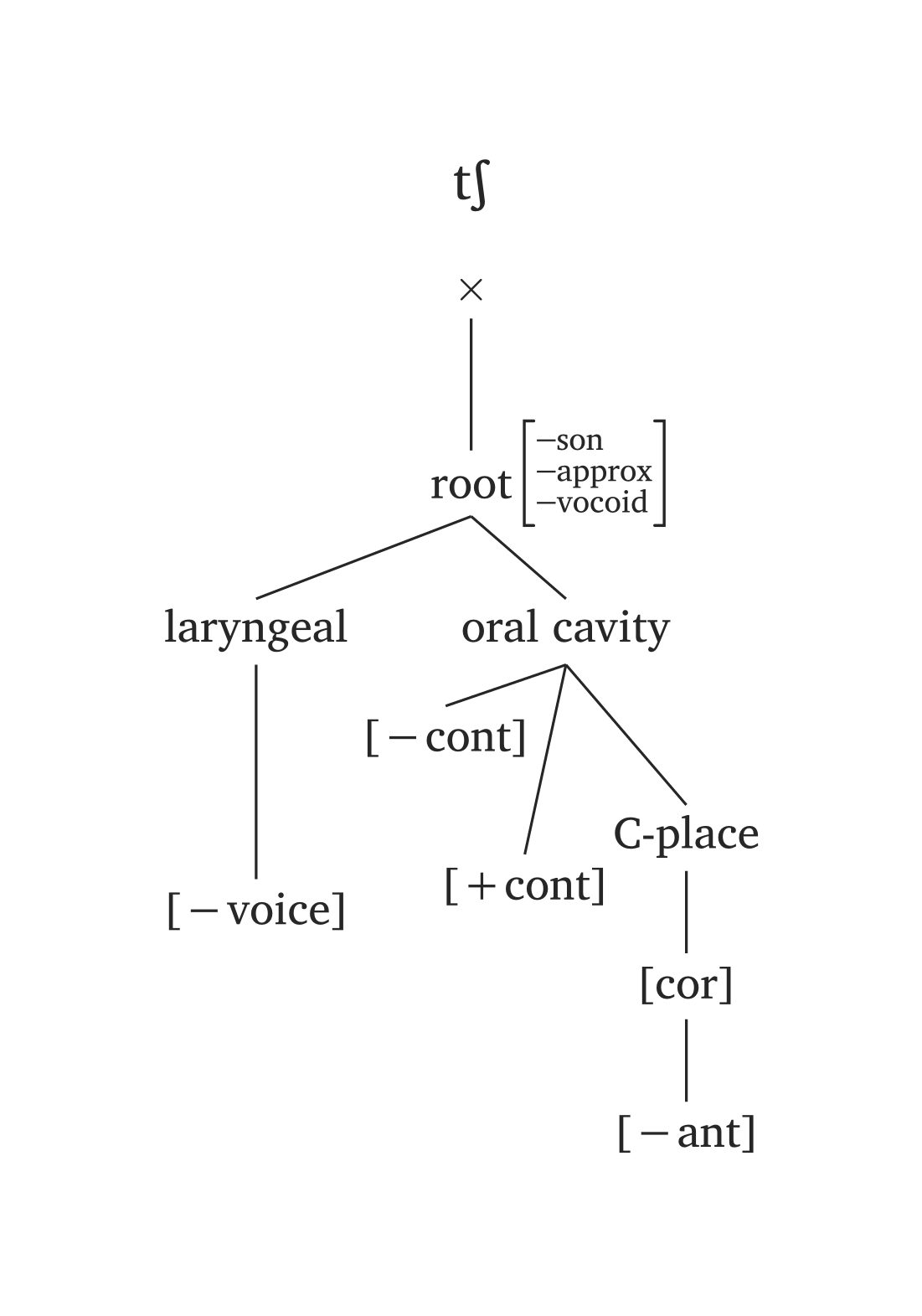
L’argument ph offre une syntaxe minimale, mais vous n’êtes pas limité aux prédéfinis. N’importe quel nœud peut être remplacé : par exemple, #geom(ph: "a", aperture: (true,)) remplace uniquement la spécification d’aperture pour le prédéfini /a/.
6.2 Arbres multiples
La fonction #geom-group() fonctionne comme un encapsuleur pour « coller » plusieurs arbres #geom() ensemble, permettant des flèches entre les arbres. Les arguments supplémentaires clés sont arrows, curved et delinks.
Les flèches référencent les nœuds par nom avec un indice d’arbre : "nasal2" fait référence à [nasal] dans l’arbre 2, "root1" à la racine dans l’arbre 1. L’argument ctrl ajuste les points de contrôle de la courbe de Bézier (directions de début et de fin). Figure 50 montre la propagation de [nasal].
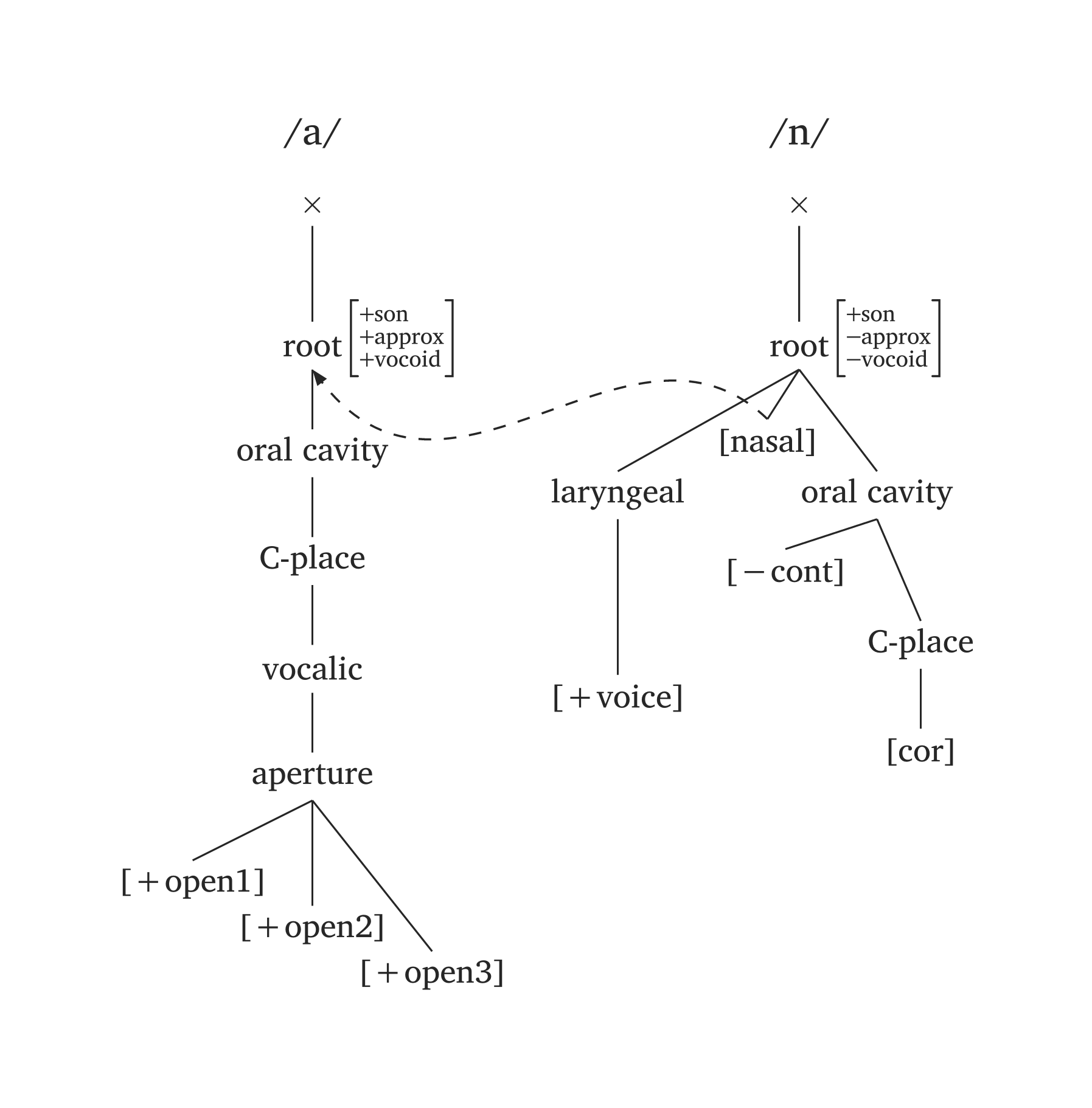
Nasalisation
#geom-group(
(ph: "/a/"),
(ph: "/n/"),
arrows: (
(from: "nasal2",
to: "root1",
ctrl: (1.1, -1.5)),
),
curved: true,
gap: 1,
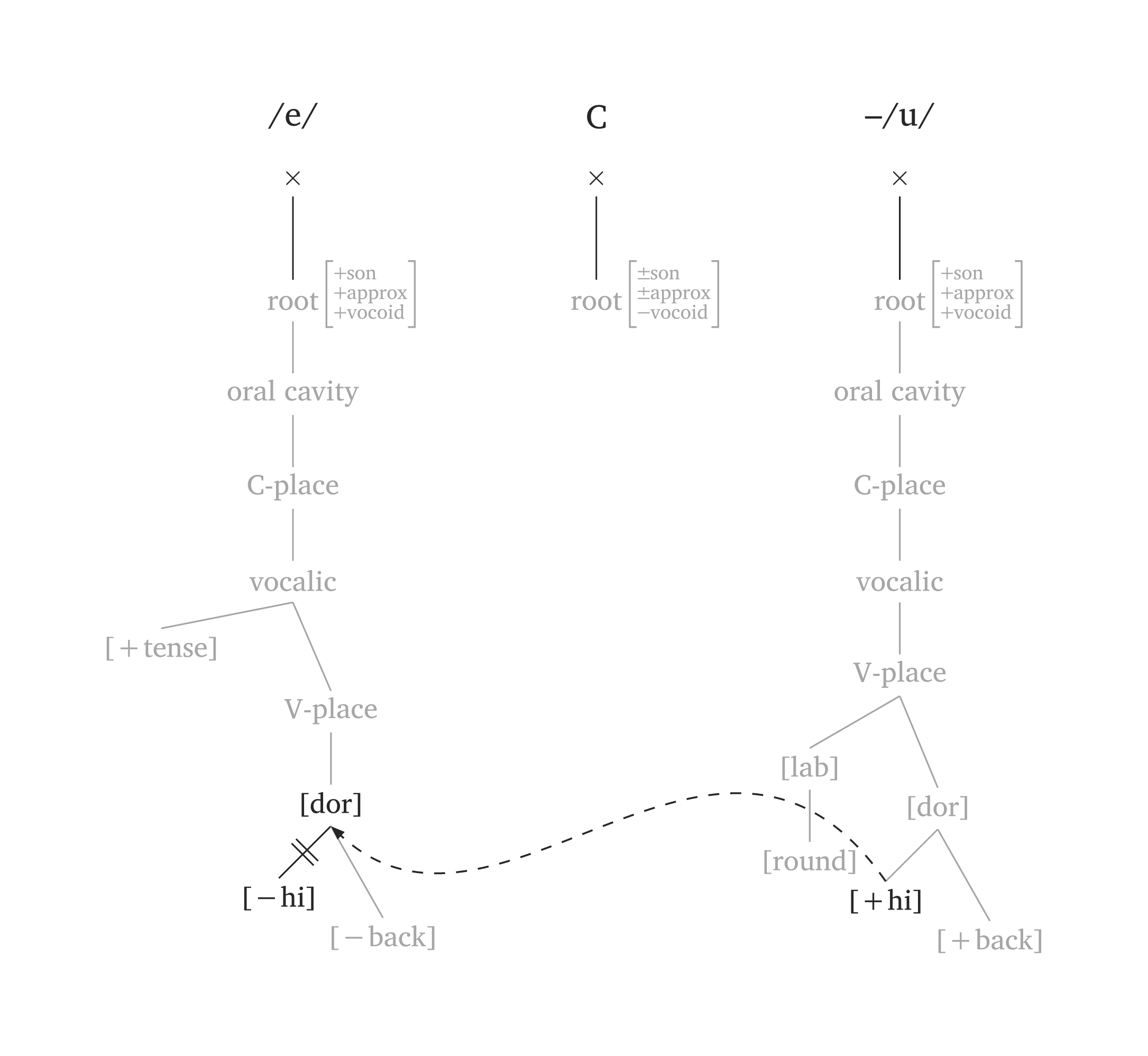
)Par défaut, #geom() utilise le modèle de Clements et Hume (1995). Définir model: "sagey" utilise les traits de hauteur (Sagey 1986) au lieu de l’aperture. L’argument highlight assombrit la représentation entière et ne met en évidence que les nœuds spécifiés. Figure 51 illustre la métaphonie où /e/ → [i] / __ C₀ /u/ :
Métaphonie (modèle Sagey)
#geom-group(
(ph: "/e/"),
(ph: "\\C"),
(ph: "/u/", prefix: "-"),
arrows: (
(from: "high3", to: "dorsal1", ctrl: (2.3, -1.5)),
),
delinks: ("high1",),
highlight: ("high1", "dorsal1", "high3"),
gap: 1.5,
model: "sagey",
)7 Théorie de l’Optimalité
La fonction #tableau() génère des tableaux OT (Prince et Smolensky 1993). Elle prend six arguments : input, candidates, constraints, violations, winner et dashed-lines. L’argument violations requiert une structure imbriquée. Le candidat winner est compté à partir de zéro. Les cellules sont automatiquement grisées après une violation fatale (!), et le symbole du doigt pointeur ☞ est ajouté pour le gagnant.

Tableau OT
#tableau(
input: "kraTa",
candidates: ("kra.Ta", "ka.Ta", "ka.ra.Ta"),
constraints: ("Max", "Dep", "*Complex"),
violations: (
("", "", "*"),
("*!", "", ""),
("", "*!", ""),
),
winner: 0, // position of winning candidate
dashed-lines: (1,), // note the comma
shade: true, // true by default
)Une fonctionnalité intéressante de #tableau() est que la fonction grise automatiquement les cellules dès qu’une violation fatale est saisie (!). De même, elle ajoute le symbole « ☞ » pour le gagnant, dont la position est extraite de l’argument winner. Les candidats peuvent également être étiquetés avec des lettres (a., b., c., …) en définissant letters: true. Lorsque les lettres sont utilisées, le symbole ☞ est placé à gauche de la lettre du candidat gagnant.
De plus, #tableau() prend en charge les structures prosodiques comme candidats.1 Vous pouvez passer des appels de fonctions prosodiques en tant que contenu en utilisant des crochets, par ex., [#syllable("mat")]. Cette approche est recommandée car elle évite les conflits avec le caractère de guillemet simple, qui est également utilisé pour le marquage de l’accent dans la notation prosodique. Figure 53 montre un exemple avec des candidats #word(). Lorsque vous passez du contenu directement, vous contrôlez l’échelle via l’argument scale de la fonction elle-même (ceci est important car les structures prosodiques sont souvent trop grandes pour un tableau). Figure 53 montre également l’argument gloss au cas où davantage d’informations seraient nécessaires pour l’input. Cet argument requiert deux chaînes de caractères (forme orthographique et traduction).
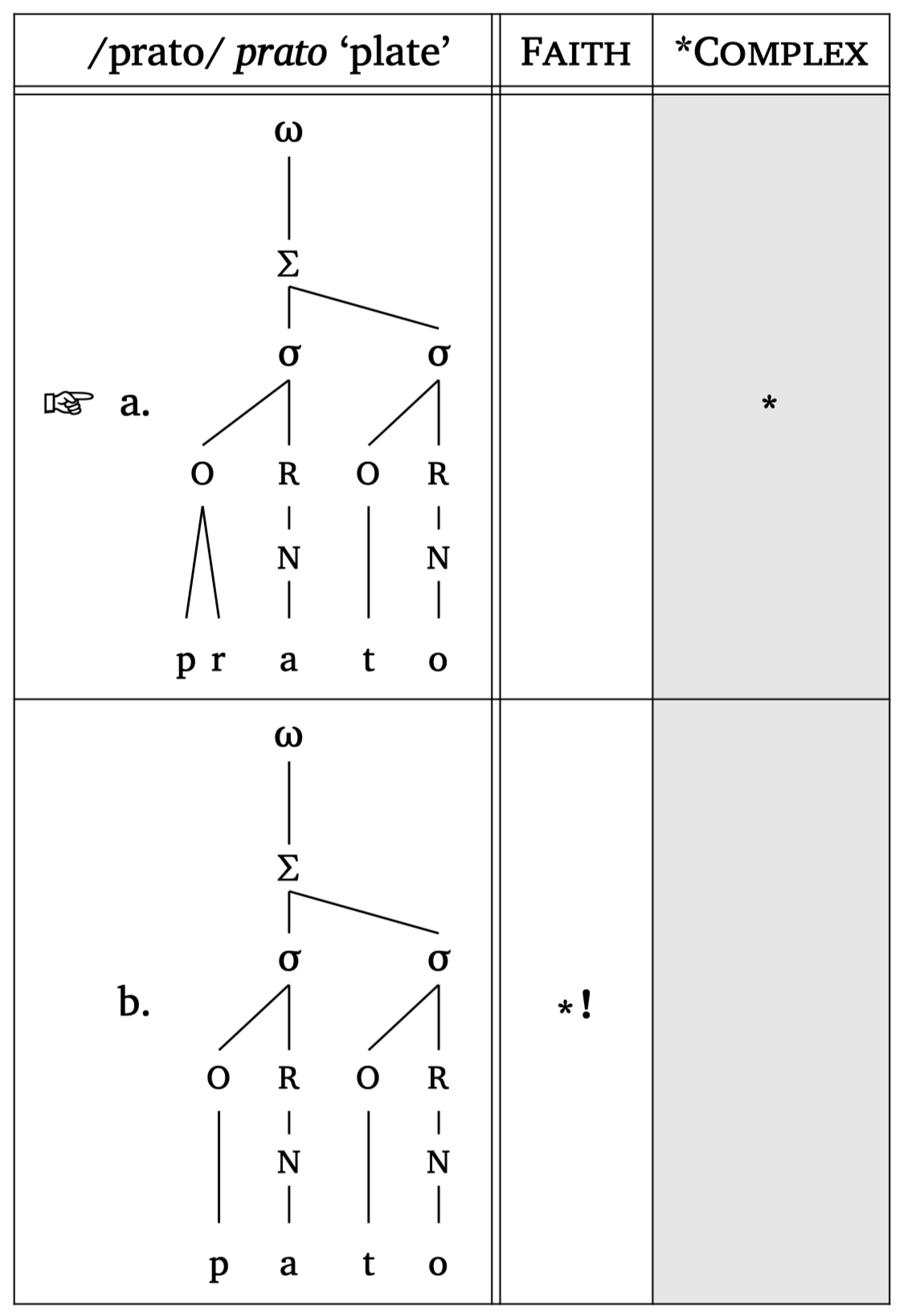
Tableau OT + prosodie
#tableau(
input: "prato",
candidates: (
[#word("('pra.to)", scale: 0.8)],
[#word("('pa.to)", scale: 0.8)],
),
constraints: ("Faith", "*Complex"),
violations: (
("", "*!"),
("", ""),
),
winner: 0,
letters: true,
gloss: ("prato", "plate"),
)Des diagrammes de Hasse pour le classement des contraintes peuvent être générés avec la fonction #hasse(). La fonction prend des tuples avec \(n\) éléments : un tuple à 2 éléments ("C1", "C2") trace un arc de classement ; un tuple à 1 élément ("C3",) crée une contrainte flottante. Le troisième élément d’un tuple contrôle le « stratum » (position verticale). Un quatrième élément peut spécifier le type de ligne : "dashed" ou "dotted".
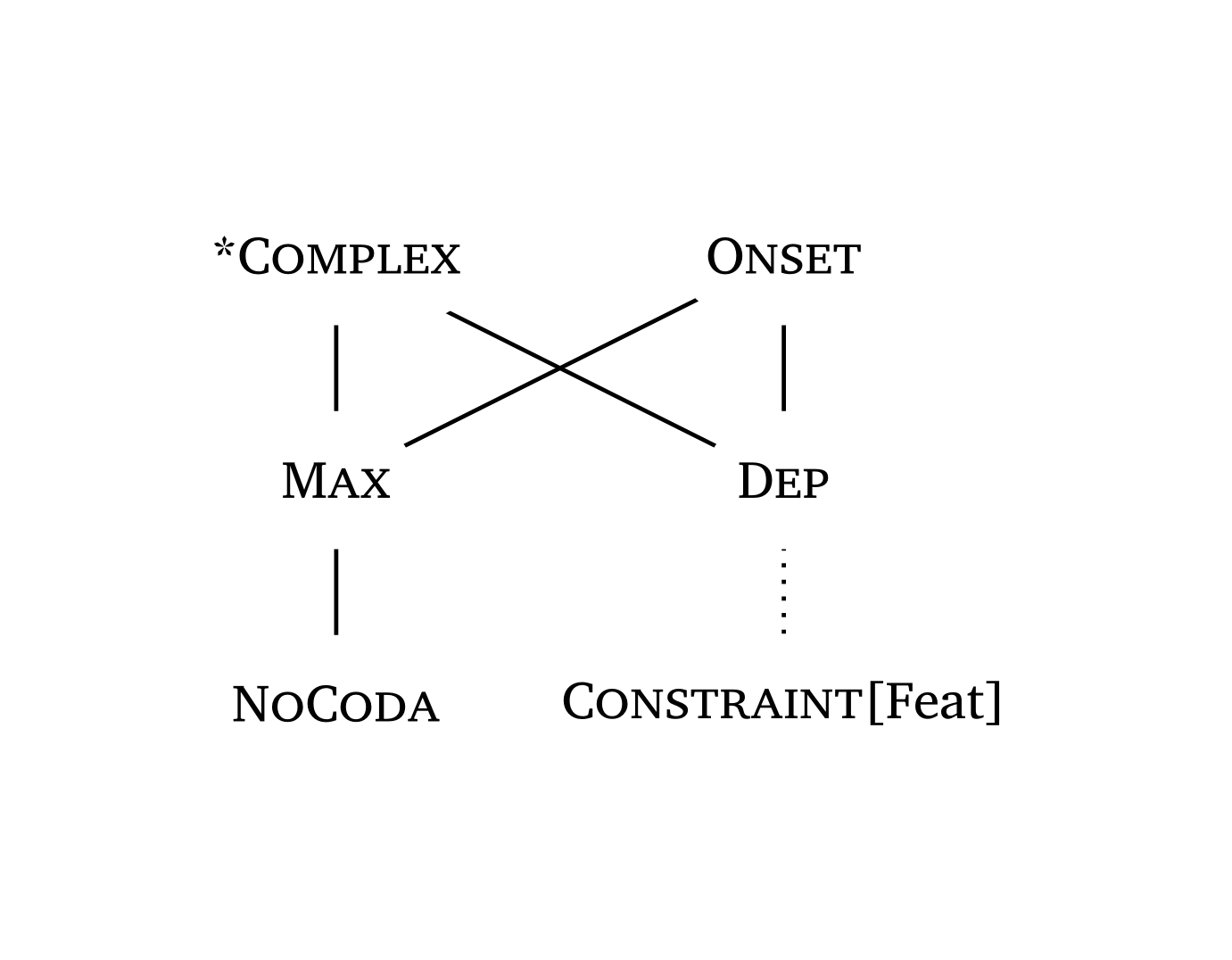
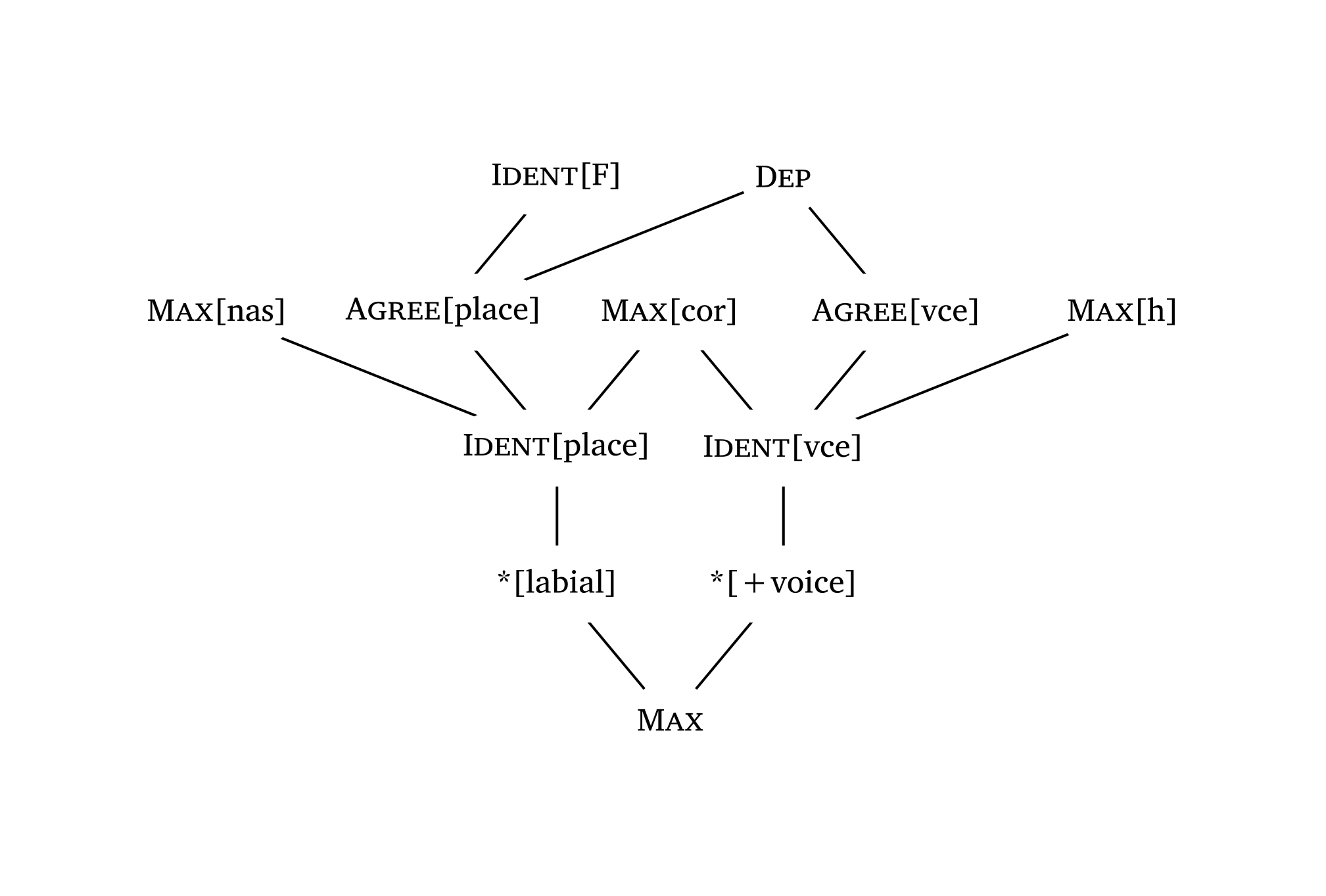
Les noms des contraintes sont automatiquement rendus en petites capitales (à l’exception des traits entre crochets).
Diagramme de Hasse avec lignes en pointillés
#hasse(
(
("*Complex", "Max", 0),
("*Complex", "Dep", 0),
("Onset", "Max", 0),
("Onset", "Dep", 0),
("Max", "NoCoda", 1),
("Dep", "Constraint[Feat]", 1, "dotted"),
),
node-spacing: 3,
)Diagramme de Hasse complexe
#hasse(
(
("Ident[F]", "Agree[place]", 0),
("Dep", "Agree[vce]", 0),
("Dep", "Agree[place]", 0),
("Max[nas]", "Ident[place]", 1),
("Max[cor]", "Ident[place]", 1),
("Max[cor]", "Ident[vce]", 1),
("Max[h]", "Ident[vce]", 1),
("Agree[place]", "Ident[place]", 1),
("Agree[vce]", "Ident[vce]", 1),
("Ident[place]", "*[labial]", 2),
("Ident[vce]", "*[+voice]", 2),
("*[labial]", "Max", 3),
("*[+voice]", "Max", 3),
),
)8 Entropie maximale
La fonction #maxent() produit un tableau MaxEnt (Goldwater et Johnson 2003; Hayes et Wilson 2008). À partir des poids de contraintes et des violations, elle calcule automatiquement \(h_i\), \(e^{-h_i}\) et \(P(y|x)\) :
\[P(y|x) = \frac{e^{-\sum_{i=1}^n w_i C_i(y,x)}}{Z(x)}\]
La colonne \(h_i\) affiche le score d’Harmonie (somme pondérée des violations) ; \(e^{-h_i}\) est la probabilité non normalisée (score MaxEnt) ; et \(P_i\) est la probabilité prédite normalisée. La fonction imprime également des barres de probabilité dans la marge droite par défaut (visualize: true, en haut et en bas dans Figure 56). Les candidats peuvent être triés du plus au moins probable avec sort: true (en bas dans Figure 56).
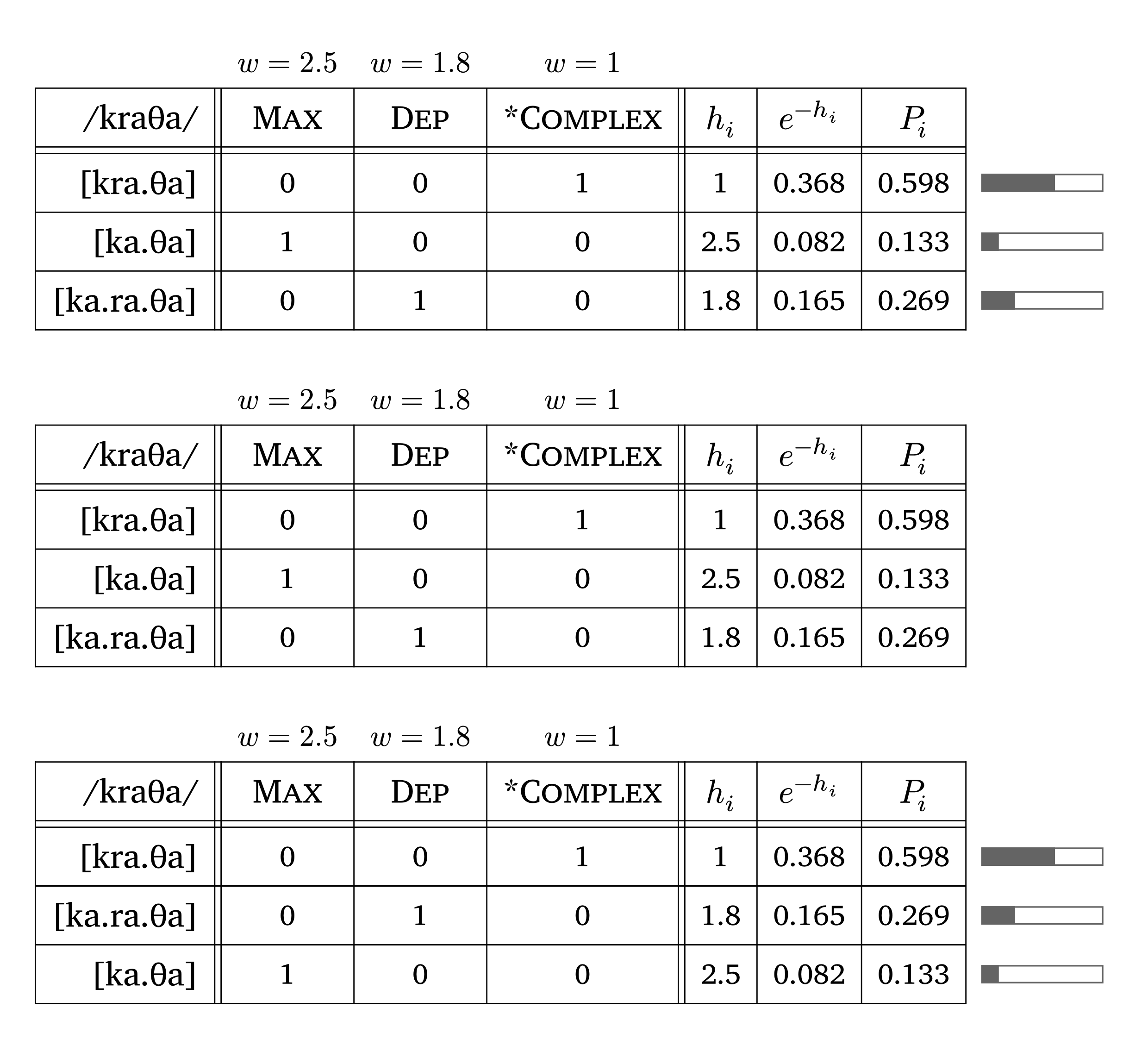
Tableau MaxEnt
#maxent(
input: "kraTa",
candidates: ("[kra.Ta]", "[ka.Ta]", "[ka.ra.Ta]"),
constraints: ("Max", "Dep", "*Complex"),
weights: (2.5, 1.8, 0.5),
violations: (
(0, 0, 1),
(1, 0, 0),
(0, 1, 0),
),
visualize: true, // show probability bars (default)
sort: true // sort candidates from most to least probable
)phonokit dispose également de fonctions pour la Grammaire harmonique (#hg()) et la Grammaire harmonique stochastique (#nhg()). Ces fonctions partagent la même syntaxe que #maxent(), à une différence importante près : #hg() et #nhg() suivent la convention selon laquelle les violations sont des nombres négatifs et le candidat ayant l’harmonie la plus élevée l’emporte, tandis que #maxent() prend des violations positives. Si vous réutilisez un tableau violations provenant de #maxent(), il faut d’abord en inverser le signe. La fonction #nhg() dérive les probabilités en simulant des évaluations (par défaut : 1000) à partir des contraintes et violations, et peut afficher la colonne de bruit. Ces fonctions sont basées sur les conventions de Flemming (2021).
9 Exemples numérotés
La fonction #ex() crée des exemples linguistiques numérotés, accompagnée de #subex-label() pour étiqueter chaque ligne au sein d’un exemple. Puisque #ex() est basée sur des tableaux, l’utilisateur peut la personnaliser avec autant de colonnes que nécessaire.
Pour utiliser cette fonction, ajoutez cette ligne après l’importation de la bibliothèque : #show: ex-rules
Exemple numéroté
// #import "@preview/phonokit:0.5.12": *
// #show: ex-rules // <- add to your document
// ...
#ex(caption: "A phonology example",
labels: (<ex-anba>, <ex-anka>),
columns: (5em, 2em, 5em))[
- #ipa("/anba/") & #a-r & #ipa("[amba]")
- #ipa("/anka/") & #a-r & #ipa("[aNka]")
] <phon-ex>Exemple numéroté ToBI
#ex(caption: "Some ToBI examples",
title: [Autosegmental transcription of intonation in English @zsiga2013sounds],
labels: (<ex-tobi1>, <ex-tobi2>),
)[
- You're a we#int("*L")rewolf?#h(1em)#int("H%", line: false)
- I'm a wer#int("*H")ewolf.#h(1em)#int("L%", line: false)
] <tobi-ex>

L’exemple entier peut être référencé comme @phon-ex, et les sous-exemples peuvent être référencés par leurs étiquettes (p. ex., @ex-anba). Spécifier les largeurs exactes des colonnes (columns: (2em, 2em, 5em, ...)) garantit un alignement parfait entre les différents exemples du document. Pour les chaînes ToBI, align: left + bottom est essentiel pour s’assurer que les lettres s’alignent avec la ligne de base du texte plutôt qu’avec les annotations tonales.
Depuis la version 0.4.6, un argument title est également disponible pour les exemples, affiché sous le numéro de légende. L’argument caption dans #ex() n’est pas imprimé directement — il est là au cas où vous souhaitez créer une table des matières des exemples avec #outline(target: figure.where(kind: "linguistic-example")).
10 Annexe
10.2 Symboles dans les représentations prosodiques
Depuis la version 0.3.7, les utilisateurs peuvent décider quels symboles sont utilisés pour les mots prosodiques, pieds, syllabes et mores via l’argument symbol, qui requiert un tableau. Les symboles par défaut sont des lettres grecques : \(\omega\), \(\Sigma\), \(\sigma\), \(\mu\).
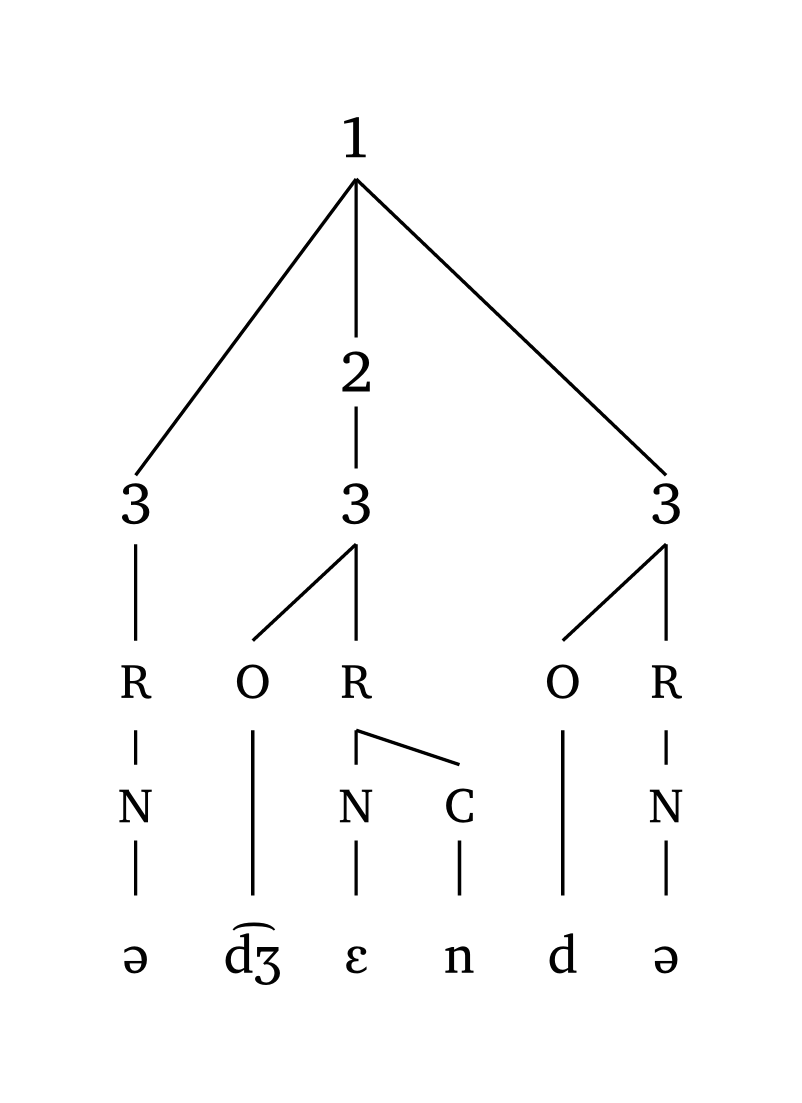
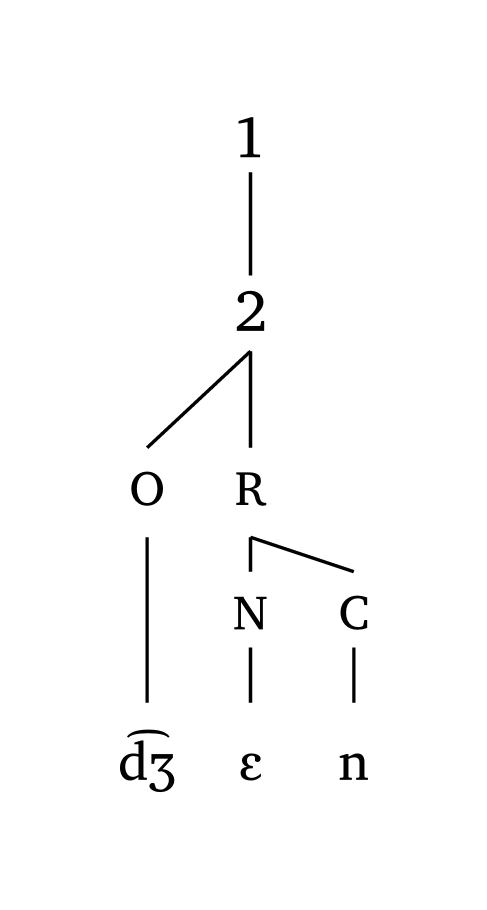
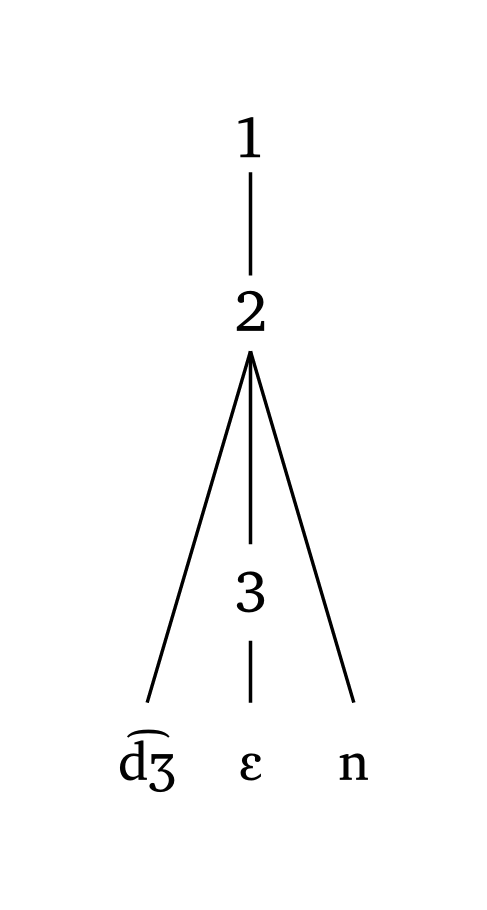
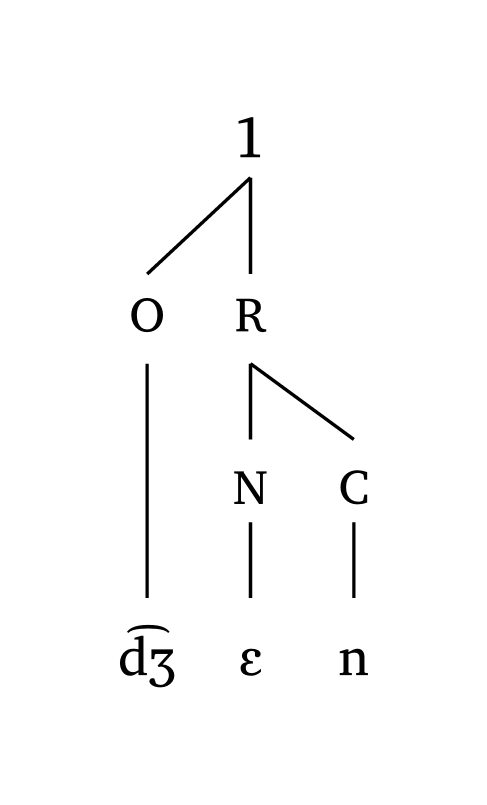
Symboles personnalisés
#word("@.( \\t dZ En).d@", symbol: ("1", "2", "3"))
#foot("\\t dZ En", symbol: ("1", "2"))
#foot-mora("\\t dZ En", symbol: ("1", "2", "3"))
#syllable("\\t dZ En", symbol: ("1",))10.3 Exportation en images
Pour utiliser phonokit sans adopter Typst comme outil principal, vous pouvez exporter n’importe quelle représentation en PNG. Créez d’abord un fichier Typst avec width: auto et height: auto dans les paramètres de page :
Configuration de page Typst pour l’exportation
#import "@preview/phonokit:0.5.12": *
#set page(width: auto, height: auto, margin: 0.5em, fill: none)
// ... your phonokit function hereCompilez ensuite depuis le terminal avec :
Compilation en PNG (bash)
typst compile file.typ file-{p}.png --ppi 500Cela génère un fichier PNG avec 500 pixels par pouce et un arrière-plan transparent.
10.4 Extras : flèches et lettres grecques
Le module extras.typ fournit des symboles utilitaires.
Flèches :
| Fonction | Description |
|---|---|
#a-r |
Flèche droite |
#a-l |
Flèche gauche |
#a-u |
Flèche vers le haut |
#a-d |
Flèche vers le bas |
#a-lr |
Flèche bidirectionnelle |
#a-ud |
Flèche bidirectionnelle verticale |
#a-sr |
Flèche ondulée vers la droite |
#a-sl |
Flèche ondulée vers la gauche |
#a-r-large |
Grande flèche droite avec espacement |
Lettres grecques (rendu droit, non italicisé) :
| Fonction | Fonction | Fonction |
|---|---|---|
#alpha |
#mu |
#tau |
#beta |
#phi |
#omega |
#gamma |
#pi |
#cap-phi |
#delta |
#sigma |
#cap-sigma |
#lambda |
#cap-omega |
Utilitaires :
#blank()— soulignement vide pour exercices à compléter ou règles SPE ; largeur ajustable :#blank(width: 4em)#extra[...]— enveloppe le contenu dans des ⟨crochets angulaires⟩ pour l’extramétricalité
Copyright © Guilherme Duarte Garcia
10.1 Comment puis-je utiliser Typst hors ligne ?
Bien que l’éditeur en ligne de Typst sur Typst.app soit très utile et pratique, la plupart d’entre nous préfèrent travailler hors ligne. Comment utiliser Typst hors ligne alors ?
L’une des meilleures options d’IDE consiste à utiliser VS Code avec l’extension Tinymist Dreamin et Varner (2024) — cette extension est donc aussi disponible pour Positron, qui est le successeur de RStudio. Tinymist est également disponible sous forme de plugin pour les utilisateurs de NeoVim. Toutes ces options fonctionnent extrêmement bien parce que Tinymist est excellent, et je n’ai rencontré aucun problème jusqu’à présent : la compilation est instantanée, et les fichiers
bibfonctionnent aussi parfaitement2Si vous utilisez Quarto, il est très facile d’utiliser phonokit avec vos fichiers
qmd. Vous devez d’abord déclarertypstcomme format. Ensuite, importez le package dans un bloc de codetypstet c’est tout. Vous pourrez alors utiliser n’importe quelle fonction. Rappelez-vous simplement que vous devez ajouter le suffixe{=typst}à chaque fois (ce que vous pouvez automatiser avec un simple snippet dans Positron, RStudio, etc. ; voir ici).