Crée : 2022/05 ; dernière mise à jour : 2024/12/05
Voici un tutoriel sur web scraping avec R pour extraire des informations d’un site web. On va extraire des données linguistiques du polonais à partir de Wikipédia. Vous aurez besoin de deux extensions R (tidyverse et rvest). En plus, il faut avoir une certaine familiarité avec HTML, CSS, et les expressions régulières.
Pour extraire des données d’un site web, il est essentiel de connaître sa structure, vu que l’on a besoin d’accéder au code source de la page pour planifier notre extraction de données, c.-à-d., il faut savoir la localisation des éléments pertinents. Si vous ne l’avez jamais fait, googlez «accéder au code source de page dans X» (où X = votre navigateur web). C’est une bonne idée aussi de googler «copier CSS ou chemin xpath d’une page», ce qui vous donnera l’adresse d’un objet spécifique dans une page.
Étape 1 : Notre tâche
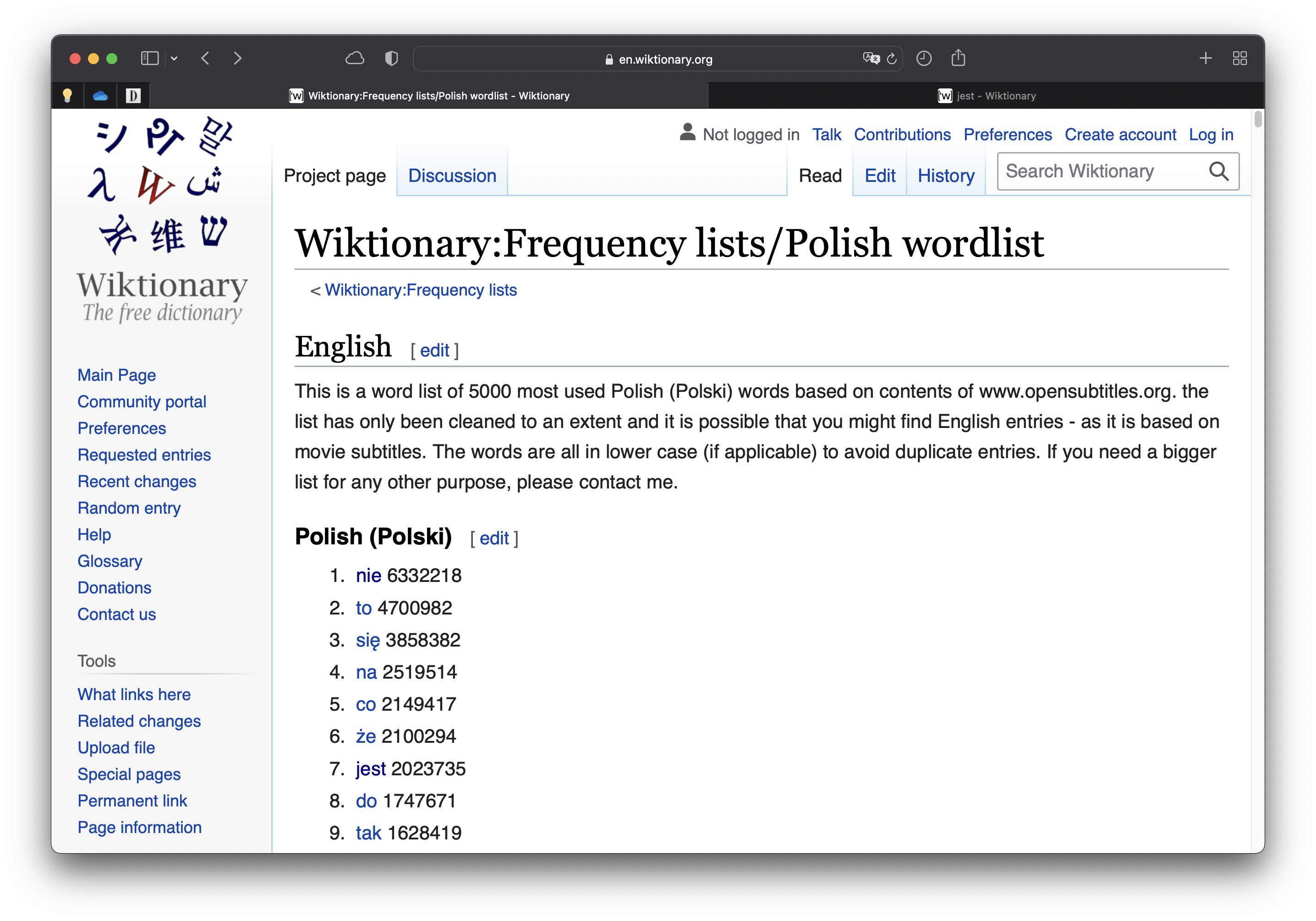
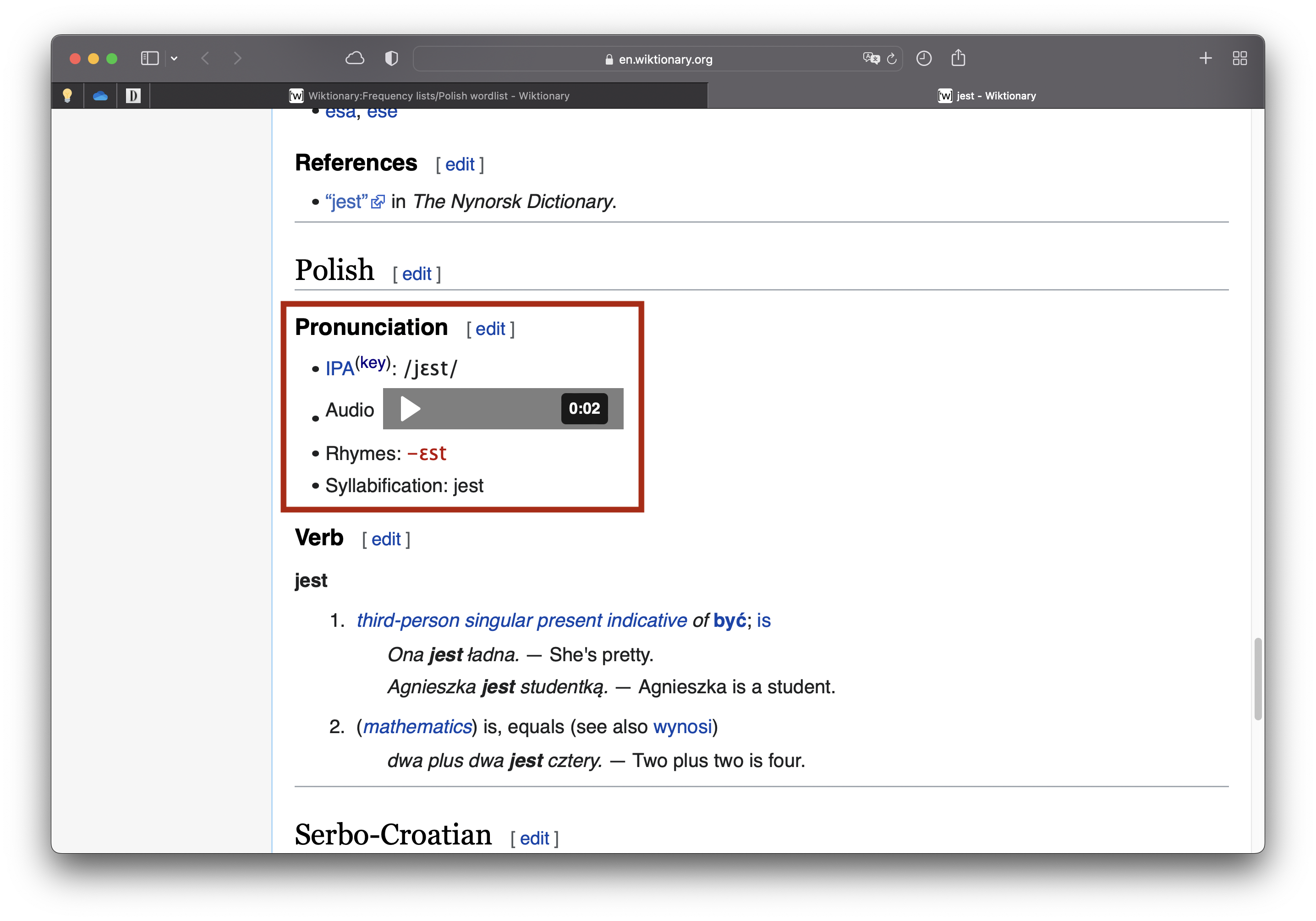
Dans cette page, on a une liste de 5 000 mots en polonais (ainsi que leur fréquence)—voyez les figures ci-dessous (cliquez pour agrandir). Si vous cliquez sur un mot, vous accédez à une nouvelle page (figure à droite). Dans la plupart des cas, cette nouvelle page contient la transcription phonétique du mot.
Liste de mots
Exemple
Notre tâche consiste à créer un tableau avec trois colonnes : Word, IPA, et Frequency. On peut trouver l’information pour Word et Frequency dans une seule page (figure à gauche ci-dessus). Toutefois, pour extraire la transcription phonétique d’un mot, il faut visiter chaque lien pour chaque mot, trouver la transcription, et l’extraire.
Étape 2 : Mots et fréquence
On commence en chargeant nos extensions et notre page web. Le code ci-dessous extrait les nœuds pertinents. Ensuite, on utilise les expressions régulières pour isoler le mot et sa fréquence pour une entrée.
Code
library(rvest)library(tidyverse)# L'adresse web pour la pagemainURL="https://en.wiktionary.org/"# Importez la pagewikiURL="https://en.wiktionary.org/wiki/Wiktionary:Frequency_lists/Polish_wordlist"pol=read_html(wikiURL)# Créez un tableau (tibble) videpolish=tibble(Word =rep(NA, 5000), IPA =rep(NA, 5000), Freq =rep(NA, 5000))# Sélectionnez les fréquencess0=pol|>html_nodes("li")# Sélectionnez seulement les entrées pour les mots# s0 contient les mots e ses fréquencess0=s0[1:5000]|>as.character()# Sélectionnez tous les mots (pas ses fréquences)s1=pol|>html_nodes("span")|>html_nodes("a")# Supprimez les lignes supérieurs (qui ne contiennent aucun mot)s1=s1[4:5003]|>as.character()
# Visualisez le premier mot pour vérifier notre code :str_extract(s1[1], ">\\w*<")|>str_remove_all(">|<")#> [1] "nie"
# Visualisez la première fréquence :str_extract(s0[1], "\\s[:digit:]+")|>str_remove_all("\\s")#> [1] NA
On a déjà complété deux tiers de notre tâche pour un seul mot. Vous ne devez jamais généraliser une tâche à tous les éléments avant d’être sûr qu’elle fonctionne parfaitement pour un seul élément. Ensuite, il faut extraire la prononciation (transcription phonétique). Cela sera plus difficile, vu qu’il s’agit d’accéder à une page additionnelle pour chaque mot.
Étape 3 : Transcriptions phonétiques
Le code ci-dessous extrait la transcription phonétique du premier mot dans notre liste. Il inclut déjà quelques corrections de bugs :
Tous les mots n’ont pas une page propre. Cela générerait une erreur
Quelques mots ont une page, mais n’ont pas une transcription API, qui serait également un problème
Les deux problèmes ci-dessus sont réglés dans le code (NA est ajouté). Cependant, il y a un problème que notre code n’est pas capable de régler complètement. Les pages pour les mots dans la liste ne sont pas exclusives au polonais. Par exemple, si un mot existe dans plusieurs langues (voyez la figure à droite ci-dessus), il aura une seule page avec de différentes sections pour chaque langue où on le trouve. Autrement dit, quand on visite une page de n’importe quel mot, c’est possible de trouver plusieurs transcriptions phonétiques. Comment pouvons-nous sélectionner seulement l’entrée polonaise ? Cela ne devrait pas être un grand problème en général, mais la structure des pages rend difficile de cibler les mots d’intérêt (étant donné la structure hiérarchique de la page).
La solution présentée dans le code est loin d’être parfaite. Vu que les entrées pour les différentes langues sont ordonnées par ordre alphabétique, le code extrait la dernière transcription phonétique trouvée dans la page.
AvertissementAttention
La solution ci-dessus ne fonctionnera pas toujours, évidemment. Si, par exemple, un mot existe en polonais et en portugais, on va extraire celui du portugais. Cette situation est toutefois rare.
Code
ipa0=str_split(s1[1], " ")[[1]][2]ipa1=str_sub(ipa0, start =8, end =-2L)ipa2=str_c(mainURL, ipa1)# Si la page n'existe pas, passez au mot suivant :if(str_detect(ipa2, "redlink")){next}ipa3=read_html(ipa2)ipa4=ipa3|>html_nodes(".IPA")|>as.character()# Si le nœud est vide (c.-à-d., aucune transcription), passez au mot suivant :if(is_empty(ipa4)){next}# Sélectionnez seulement les transcriptions avec // ou [] :ipa4=ipa4[str_detect(ipa4, pattern =">\\[|\\/<")]if(is_empty(ipa4)){next}# Extrayez la dernière transcription :ipa4=ipa4[length(ipa4)]ipa5=str_extract(ipa4, "(\\[|/)\\w*(\\.\\w*)*(\\]|/)")ipa6=str_replace_all(ipa5, "/|\\[|\\]", "")ipa6#> [1] "ˈɲɛ"
Étape 4 : Combinez les étapes 1–3
Le code ci-dessous combine toutes les étapes dans un for-loop qui remplira le tableau créé plus tôt. La fin du code fait quelques ajustements de classe et enregistre le résultat dans un fichier RData. Gardez à l’esprit que le code peut prendre 10–20 minutes pour s’exécuter.
Code
rm(list=ls())library(rvest)library(tidyverse)mainURL="https://en.wiktionary.org/"pol=read_html("https://en.wiktionary.org/wiki/Wiktionary:Frequency_lists/Polish_wordlist")polish=tibble(Word =rep(NA, 5000), IPA =rep(NA, 5000), Freq =rep(NA, 5000))# Sélectionnez les fréquencess0=pol|>html_nodes("li")# Sélectionnez seulement les entrées pour les motss0=s0[1:5000]# Sélectionnez tous les mots (pas leurs fréquences)s1=pol|>html_nodes("span")|>html_nodes("a")s1# Supprimez les lignes supérieures (qui ne contiennent aucun mot)s1=s1[4:5003]# Loop pour ajouter les mots :for(iin1:nrow(polish)){# Sélectionnez le motword=str_extract(s1[i], ">\\w*<")|>str_remove_all(">|<")polish$Word[i]=word# Extraction de la transcriptionipa0=str_split(s1[i], " ")[[1]][2]ipa1=str_sub(ipa0, start =8, end =-2L)ipa2=str_c(mainURL, ipa1)# Si la page n'existe pas, passez au mot suivant :if(str_detect(ipa2, "redlink")){next}ipa3=read_html(ipa2)ipa4=ipa3|>html_nodes(".IPA")# Si le nœud est vide (c.-à-d., aucune transcription), passez au mot suivant :if(is_empty(ipa4)){next}# Sélectionnez seulement les transcriptions avec // ou [] :ipa4=ipa4[str_detect(ipa4, pattern =">\\[|\\/<")]if(is_empty(ipa4)){next}# Sélectionnez la dernière transcriptionipa4=ipa4[length(ipa4)]ipa5=str_extract(ipa4, "(\\[|/)\\w*(\\.\\w*)*(\\]|/)")ipa6=str_replace_all(ipa5, "/|\\[|\\]", "")polish$IPA[i]=ipa6# Extrayez les fréquencespolish$Freq[i]=str_extract(s0[i], "\\s[:digit:]+")|>str_remove_all("\\s")}polishtail(polish)polish=polish|>mutate(across(where(is.character), as.factor))# Enregistrez le fichier en format RData:save(polish, file ="Polish.RData")