# ggplot(data = ..., aes(x = ..., y = ...)) +
#
library(tidyverse)
donnees = read_csv("donnees/sampleData.csv")
# la première couche de la figure :
ggplot(data = donnees, aes(x = group, y = testA)) 
@barnier_R (chap. 8)
La visualisation de données permet d’optimiser la compréhension des patrons et des résultats. L’extension la plus complète pour créer des figures en R est appelée ggplot2 — cette extension est chargée automatiquement quand on charge tidyverse, heureusement. Bien qu’il ait d’autres extensions, on va se concentrer sur ggplot2 pour notre cours.
Pour être capable de générer des figures optimales, vous devez vous concentrer sur deux éléments :
Comme déjà mentionnée en classe, la deuxième partie est plus facile que la première, ce qui surprend certains. Spécifiquement, vous devez connaître quel genre de figure sera approprié étant données les variables qui seront visualisées.
L’idée principale du ggplot2 implique l’utilisation des « couches » d’informations qui sont connectées par le symbole d’addition +. On commence avec la couche de base en utilisant la fonction ggplot(). Cette couche indique l’origine des données, ainsi que les variables qui seront utilisées dans chaque axe. Pour l’exemple ci-dessous, on utilise le fichier sampleData.csv, téléchargé dans la dernière séance.
# ggplot(data = ..., aes(x = ..., y = ...)) +
#
library(tidyverse)
donnees = read_csv("donnees/sampleData.csv")
# la première couche de la figure :
ggplot(data = donnees, aes(x = group, y = testA))
Lorsqu’on exécute la ligne en question, on voit que le résultat serait simplement une toile vide. R sait quelles données seront visualisées, mais on n’a pas encore indiqué le type de visualisation souhaité.
L’argument data indique l’objet qui contient nos données (un tibble, un data frame, etc.). Dans la fonction aes(), on spécifie les variables pour les axes x et y. Jusqu’ici, on a pas décidé quel type de figure on va créer. Pour prendre cette décision, il faut évaluer les variables en question.
Voici quelques règles générales. Il y a quelques exceptions à ces règles, mais vous pouvez les considérer comme les règles de base.
y contient la variable de réponse, c’est-à-dire les « résultats » dans les données. Par exemple, si je compare les notes de deux groupes de participants, les notes seront dans l’axe y.x contient la variable qui influe sur notre y. Par exemple, les deux groupes de participants mentionnés ci-dessus. On peut ajouter d’autres variables en utilisant de différentes couleurs, des tailles, des formes, etc.x contient une variable continue, un nuage de points est souvent utilisé avec la fonction geom_point(). On peut ajouter une ligne de régression à la figure en utilisant la fonction stat_smooth() ou geom_smooth() (cette droite sera accompagnée d’une région ombrée représentant les intervalles de confiance à 95 %)x contient une variable catégorique, un graphique en barres (horizontales) est souvent utilisé avec les fonctions geom_bar() ou geom_col(). On peut utiliser aussi la boîte à moustaches avec geom_boxplot(), des barres d’erreur avec stat_summary(), etc.Vu que l’axe x est catégorique et que l’axe y est continu, on pourrait créer une boîte à moustaches avec geom_boxplot(). Cela sera notre deuxième couche :
ggplot(data = donnees, aes(x = group, y = testA)) +
geom_boxplot()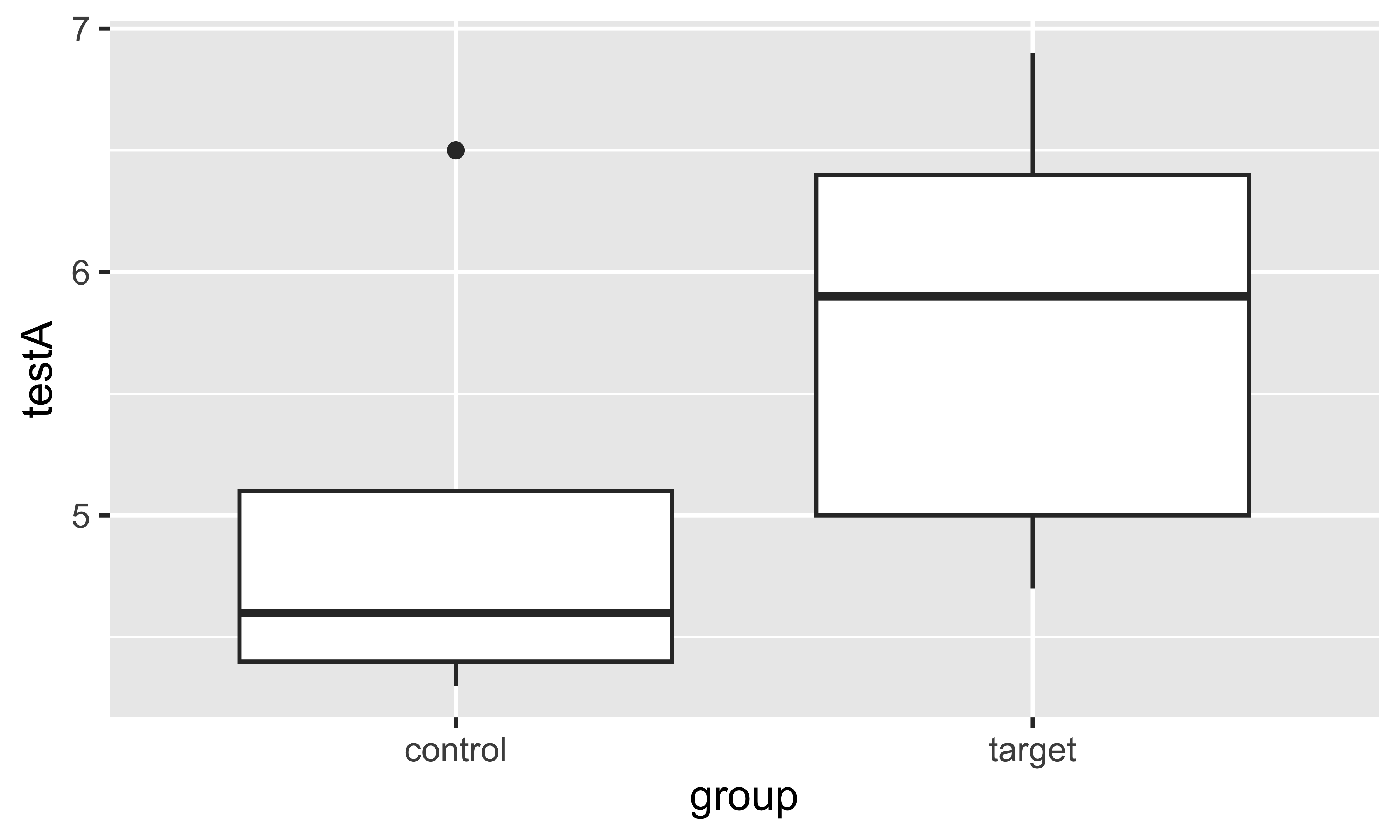
Ensuite, on peut ajouter n’importe combien de couches à la figure. Par exemple, vu que la boîte à moustaches ne montre pas les moyennes, on pourrait inclure une troisième couche en utilisant la fonction stat_summary(), qui crée les moyennes ainsi que les erreurs standards de la moyenne. Pour différencier les erreurs des boîtes, on peut utiliser des couleurs :
ggplot(data = donnees, aes(x = group, y = testA)) +
geom_boxplot() +
stat_summary(color = "darkviolet") +
theme_minimal()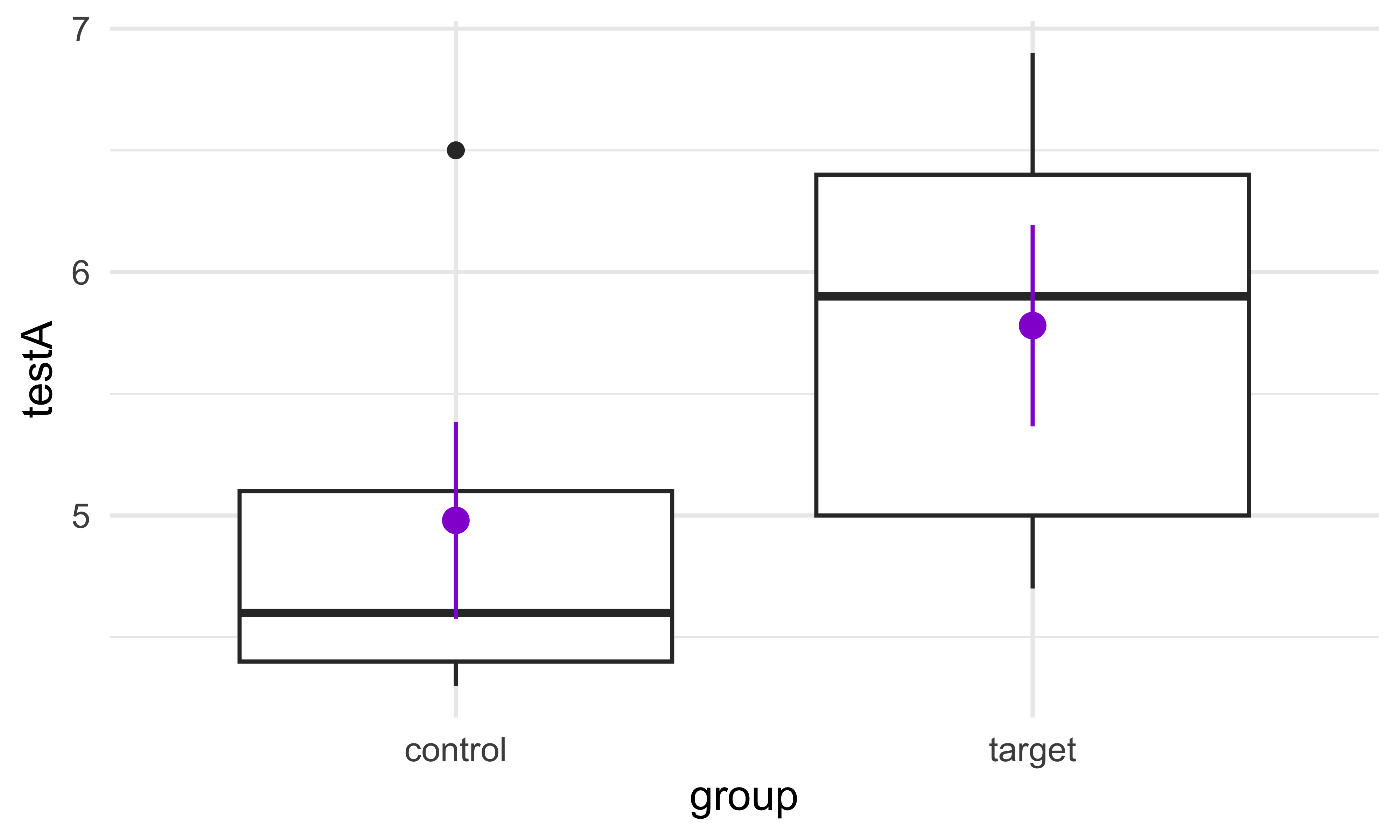
Les boîtes sont dans la deuxième couche ici; les moyennes sont dans la troisième couche (si on change l’ordre, les moyennes seraient derrière les boîtes)
C’est un bon moment pour examiner notre tableau :
donnees
#> # A tibble: 10 × 5
#> participant group testA testB testC
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 subject_1 control 4.4 6.9 6.3
#> 2 subject_2 control 6.5 9.9 6.1
#> 3 subject_3 control 5.1 6.7 5.7
#> 4 subject_4 control 4.6 9.6 5.5
#> 5 subject_5 control 4.3 6.1 6.4
#> 6 subject_6 target 6.9 8.8 5.1
#> 7 subject_7 target 4.7 6.4 4.7
#> 8 subject_8 target 5 6.8 6.9
#> 9 subject_9 target 6.4 9.3 5.8
#> 10 subject_10 target 5.9 9.1 4.5On a déjà vu en classe qu’il s’agit d’un tableau large (donc, pas tidy). Par conséquent, c’est difficile de créer une figure dont l’axe y montre toutes les notes des tests A, B et C : la fonction aes() dans ggplot() ne permet qu’une colonne pour chaque axe du graphique. Donc, avant de développer la figure en question, il faut transformer les données vers le format tidy en utilisant la fonction pivot_longer() (consultez la page de la deuxième séance ici) :
long = donnees |>
pivot_longer(names_to = "test",
values_to = "note",
cols = testA:testC)
long
#> # A tibble: 30 × 4
#> participant group test note
#> <chr> <chr> <chr> <dbl>
#> 1 subject_1 control testA 4.4
#> 2 subject_1 control testB 6.9
#> 3 subject_1 control testC 6.3
#> 4 subject_2 control testA 6.5
#> 5 subject_2 control testB 9.9
#> 6 subject_2 control testC 6.1
#> 7 subject_3 control testA 5.1
#> 8 subject_3 control testB 6.7
#> 9 subject_3 control testC 5.7
#> 10 subject_4 control testA 4.6
#> # ℹ 20 more rowsMaintenant, on peut facilement copier et ajuster le code de la figure ci-dessus pour créer un graphique général des notes à partir de notre nouvel objet long :
ggplot(data = long, aes(x = group, y = note)) +
geom_boxplot() +
stat_summary(color = "darkviolet")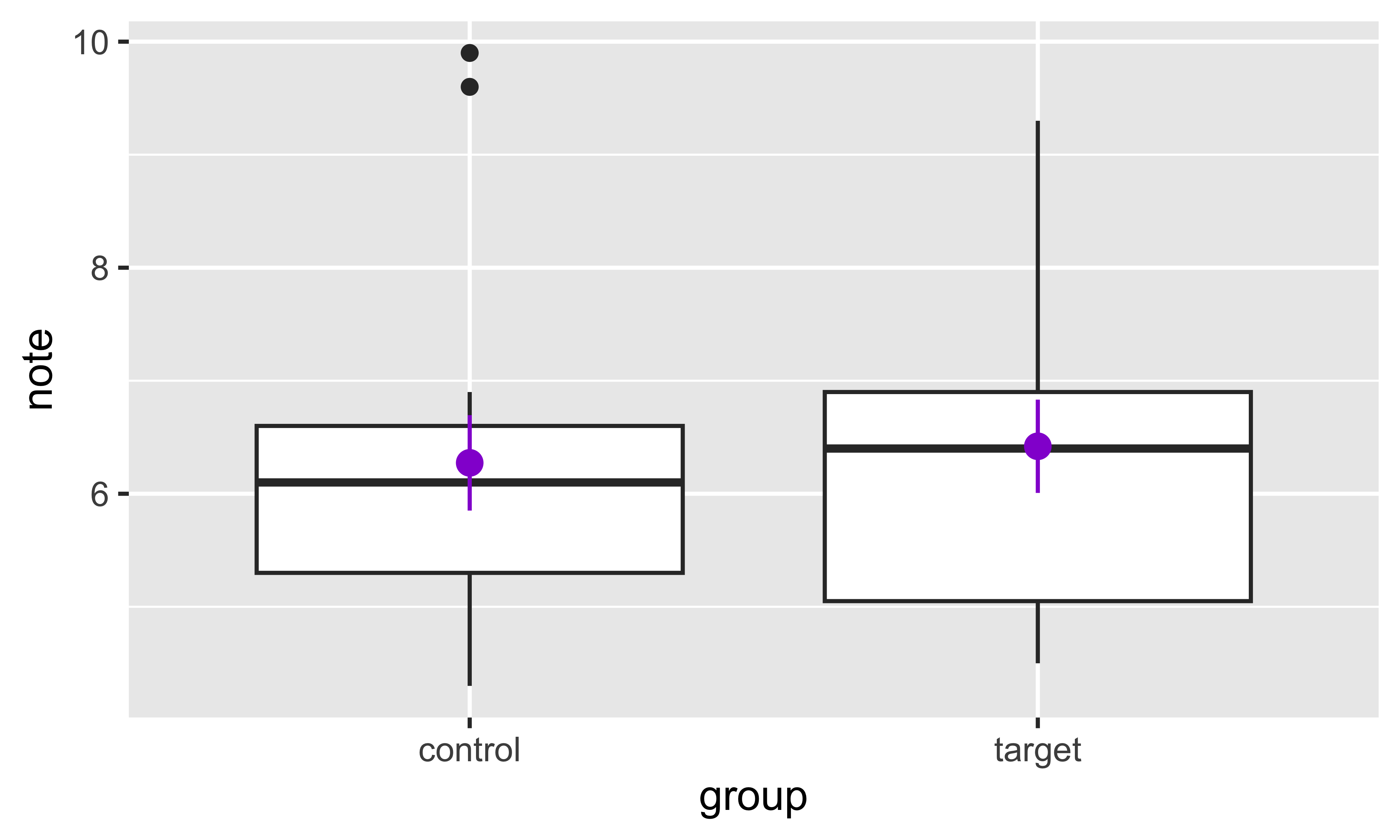
long Notez que l’argument pour l’axe y est note maintenant.Finalement, on peut faire quelques ajustes esthétiques. C’est toujours une bonne idée d’avoir des étiquettes informatives et claires. Ici, on change aussi la transparence des boîtes (alpha = ...) et on ajoute un titre.
ggplot(data = long, aes(x = group, y = note)) +
geom_boxplot(alpha = 0.5) +
stat_summary(color = "darkviolet") +
1 labs(x = "Groupe",
y = "Note",
title = "Notre graphique",
subtitle = "Un sous-titre ici") +
theme_minimal()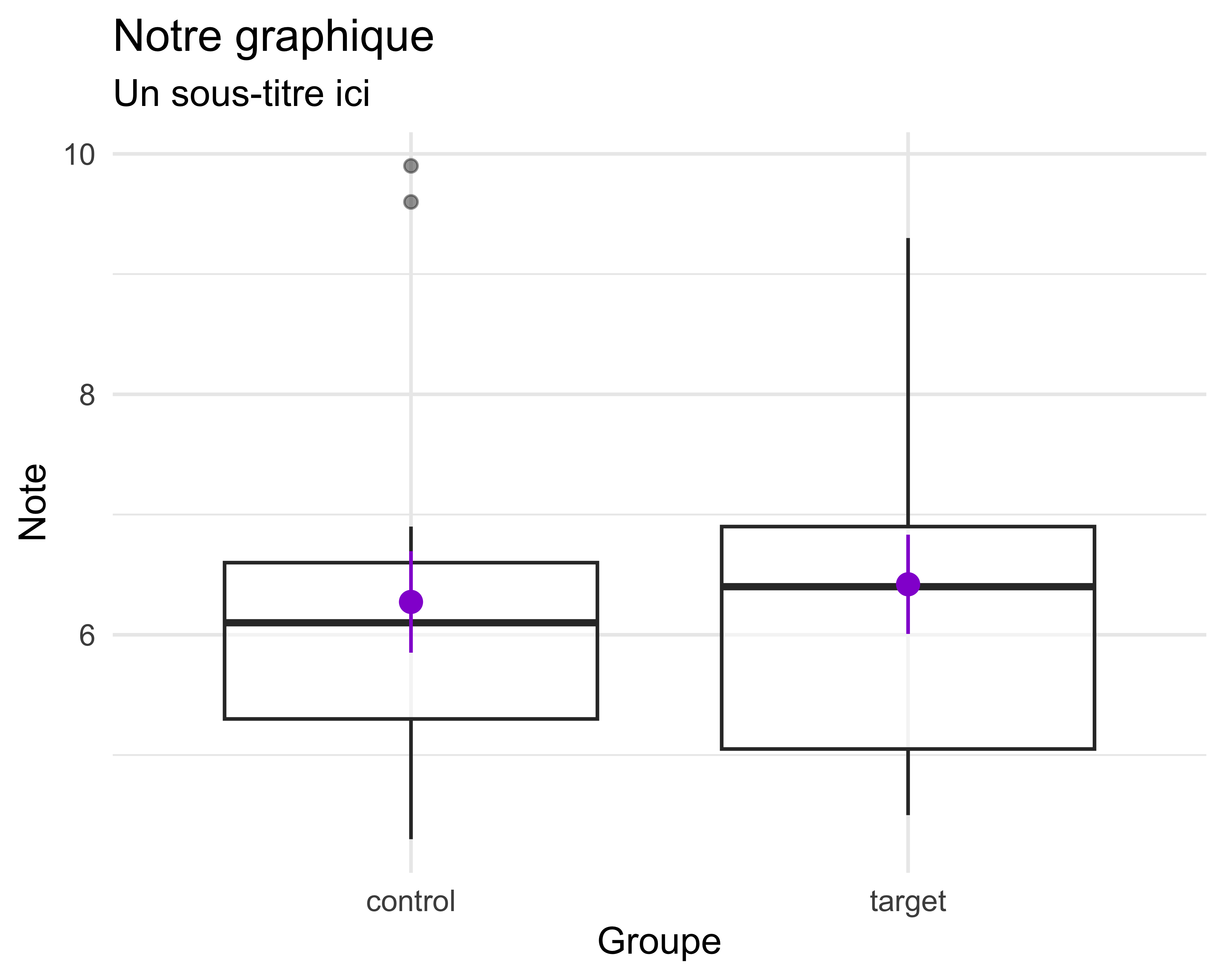
L’argument alpha exige un nombre de 0 (complètement transparent) à 1 (solide). Il y a une liste de thèmes disponibles, spécialement si on installe l’extension ggthemes.
Normalement, avant de visualiser nos données, on a besoin de faire quelques ajustements. L’extension dplyr @barnier_R (chap. 10), incluse dans tidyverse, nous permet d’exécuter plusieurs opérations utiles avec des fonctions intuitives. En plus, on peut facilement enchaîner ces opérations avec le pipe. Parmi les fonctions les plus utiles, vous devez être capable d’utiliser :
filter() : pour subdiviser les données (c’est-à-dire sélectionner les lignes qui nous intéressent ou qui ne nous intéressent pas)mutate() : pour créer des nouvelles colonnesarrange() : pour ordonner les données à partir des n’importe quelle·s variable·sgroup_by() : pour grouper les données (normalement utilisé avant de créer un résumé statistique, par exemple)select() : pour sélectionner des colonnessummarize() : pour générer un résumé des données (le résultat sera un nouveau tibble)Si on utilise ces fonctions et le pipe, on peut exécuter plusieurs commandes de façon rapide et intuitive. Par exemple, imaginons le scénario suivant :
long (ligne 1)test (ligne 3)Les opérations sont toutes enchaînées avec le pipe (|>), ce qui rend la séquence facile à comprendre. Lorsqu’on exécute le code, on constate que la moyenne pour testA n’est pas calculé grâce à la ligne 2.
long |>
filter(test != "testA") |>
mutate(langue = "japonais") |>
group_by(test) |>
summarize(moyenne = mean(note))
#> # A tibble: 2 × 2
#> test moyenne
#> <chr> <dbl>
#> 1 testB 7.96
#> 2 testC 5.7On peut également filtrer les données dans la fonction ggplot, c’est-à-dire dans un seule pas :
ggplot(data = long |> filter(test != "testA"),
aes(x = test, y = note)) +
stat_summary() +
theme_minimal()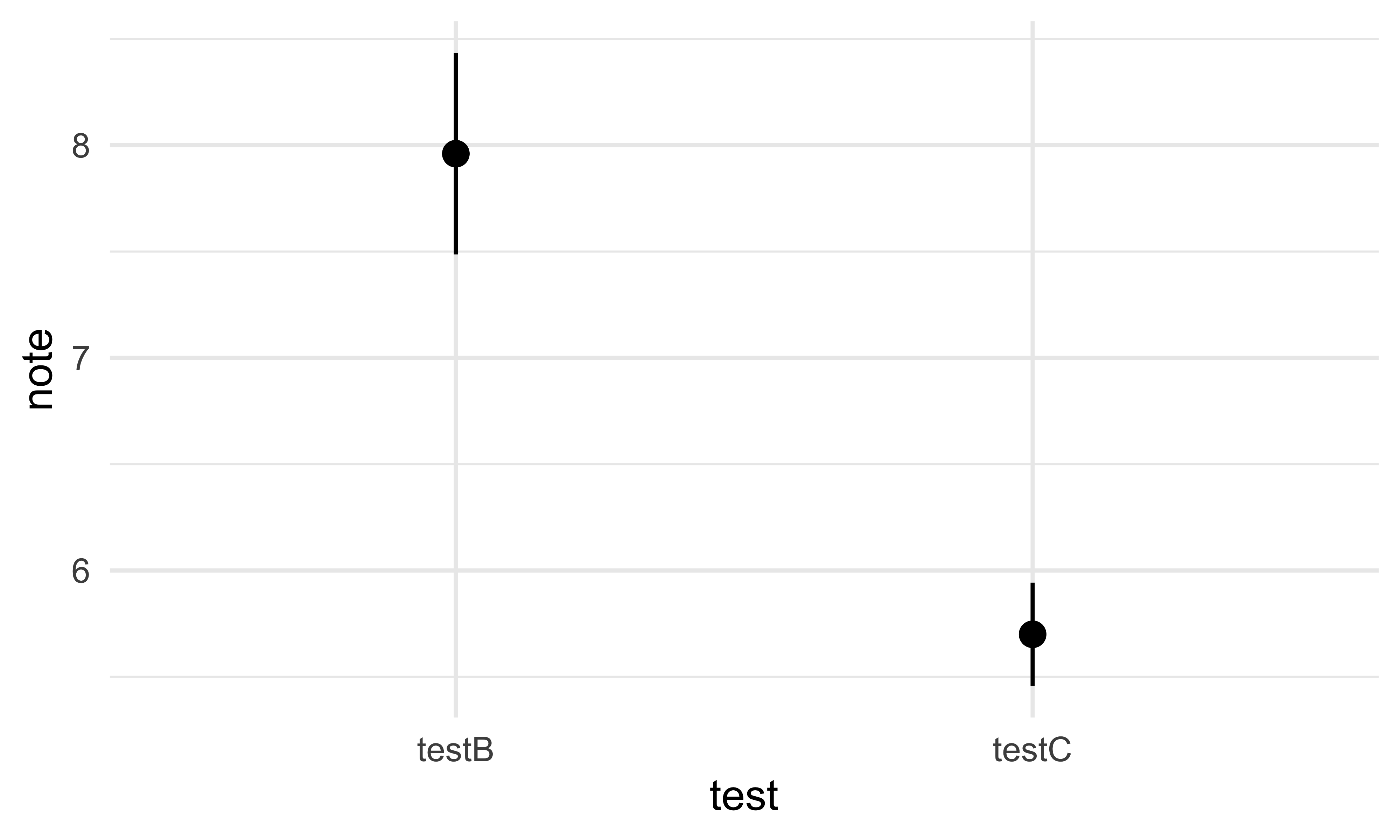
Finalement, on peut enchaîner les opérations de dplyr avec ggplot.
long |>
filter(test != "testA") |>
mutate(langue = "japonais") |>
group_by(test) |>
summarize(moyenne = mean(note)) |>
1 ggplot(data = _, aes(x = test, y = moyenne)) +
geom_col() +
theme_minimal()|> avant ggplot, mais + dans ggplot
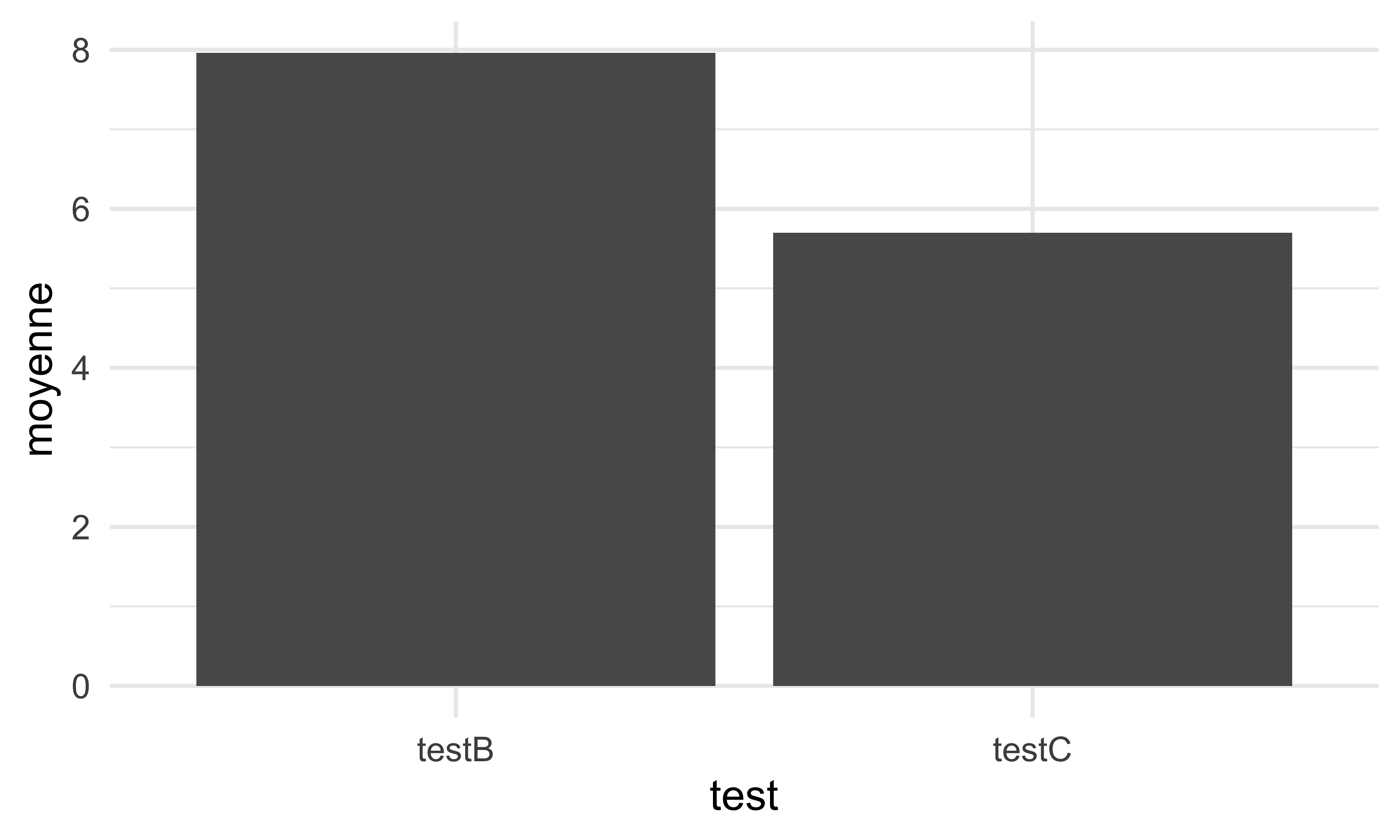
Ici, le code n’a pas du sens, vu que la fonction stat_summary(geom = "bar") peut calculer les moyennes pour nous. En plus, ce type d’enchaînement peut être difficile d’interpréter dans notre script. Par conséquent, c’est mieux de séparer les étapes : on prépare les données avant de les visualiser.
Comme d’habitude, c’est une bonne idée de créer un
scriptpour les exercices de pratique dans chaque chapitre.
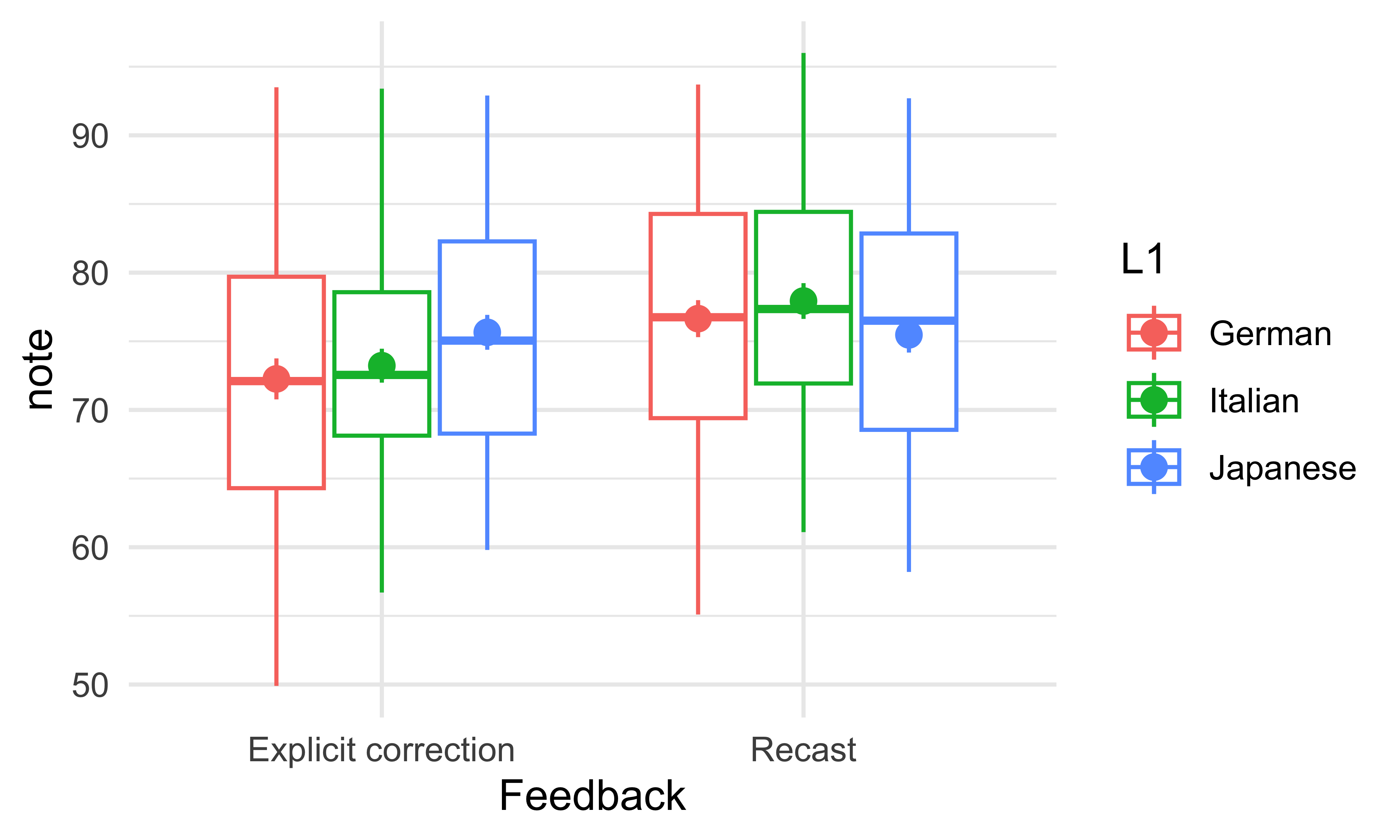
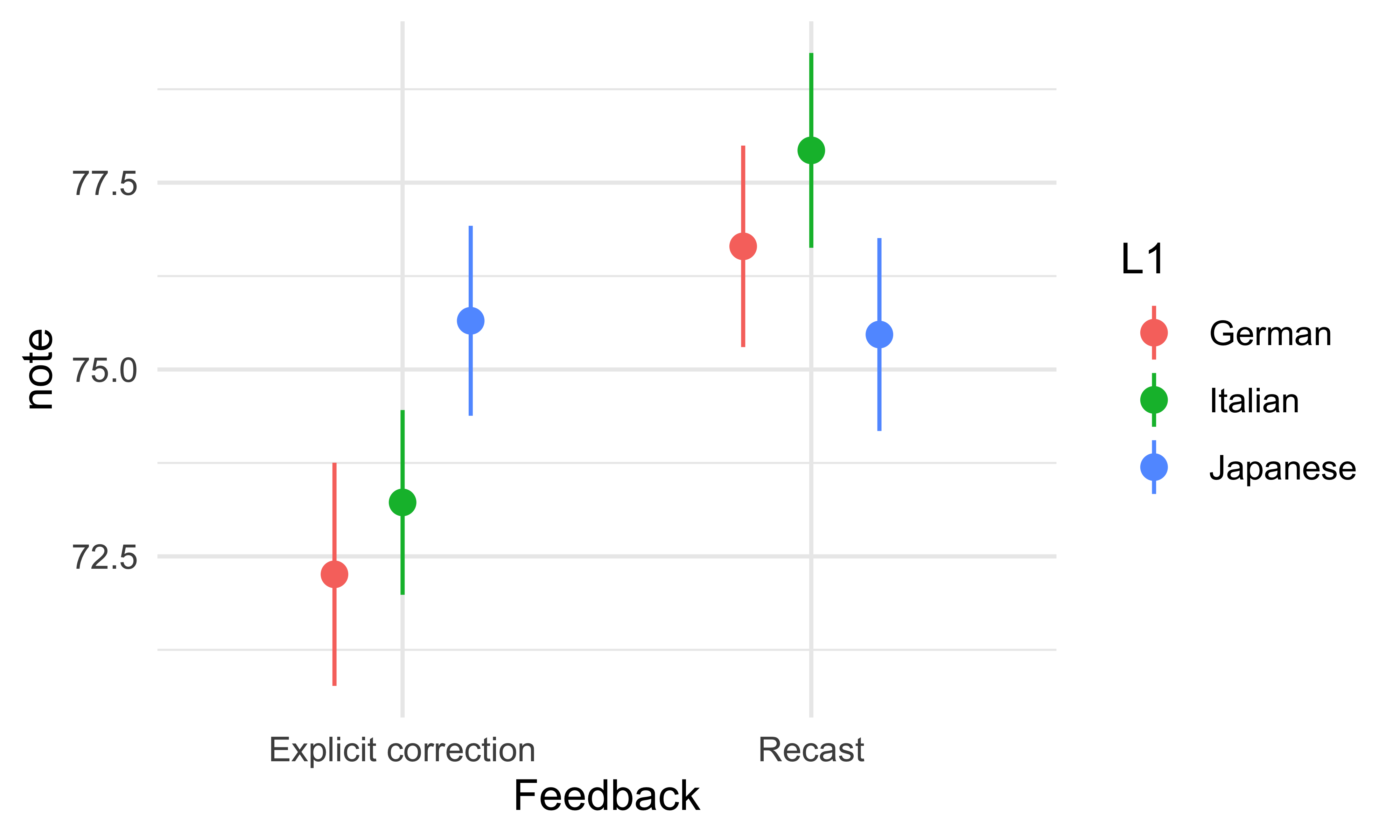
Question 1. Importez le fichier feedbackData.csv et examinez la structure des données avec la fonction glimpse(). Vous pouvez utiliser la fonction summary() aussi. Il s’agit d’une étude hypothétique sur l’impact de la rétroaction sur la performance des étudiants et des étudiantes dans deux types de tâches, A et B. Il y a deux genres de rétroaction dans les données : la correction explicite et la reformulation. Après avoir examiné rapidement les données, éliminez les colonnes de la tâche B (on va se concentrer sur la tâche A). Il y a trois groupes de participants (trois langues maternelles) : German, Italian, Japanese.
Question 2. Le type de rétroaction affecte-t-il la performance des participants dans la tâche A? Créez une boîte à moustaches pour répondre à la question.
Question 3. La langue maternelle des participants a-t-elle un effet sur leurs notes? Vous pouvez continuer à utiliser la boîte à moustaches ici.
️ Question 4. Maintenant, ajouter au graphique de la question 3 une couche avec les moyennes et les erreurs standards. Quel problème rencontrez-vous?
Les conclusions qu’on tire d’une figure dépendent de plusieurs facteurs, dont certains sont purement esthétiques. Comparez les deux versions du graphique ci-dessous : le changement de l’axe
yaffecte notre perception. Consultez l’appli ici.
Question 5. La quantité d’heures d’étude (Hours) a-t-elle un rôle sur la performance des participants? Quel type de figure pourriez-vous créer ici? Pour mettre en évidence des tendances dans les données, ajoutez une ligne de régression au graphique.
Question 6. Ajustez les étiquettes de la figure créée dans la question 5 et changez la taille, la couleur, et la transparence des points.
En effet, notre analyse statistique sera basée sur ce type de relation : la variable dans l’axe
xest-elle importante pour prévoir les résultats dans l’axey? La seule différence sera la supposition de que cette relation sera complètement linéaire (pour la première partie du cours).
Copyright © Guilherme Duarte Garcia